머신러닝 하다 보면 꼭 만나는 그 녀석
머신러닝을 공부하다 보면 손실 함수(loss function) 이야기가 빠지지 않잖아요. 그중에서도 KL 발산(Kullback-Leibler Divergence)이라는 개념은 정말 여기저기서 등장하거든요. VAE(변분 오토인코더)를 만들 때도, LLM을 RLHF로 파인튜닝할 때도, 심지어 지식 증류(Knowledge Distillation)에서도 핵심 역할을 해요. 그런데 막상 "KL 발산이 뭐야?"라고 물으면 수식만 떠올리고 직관적으로 설명하기 어려운 분들이 많을 거예요.
최근 공유된 한 블로그 글이 바로 이 KL 발산을 6가지 반(6.5가지)의 서로 다른 직관으로 풀어냈는데요, 수식 없이도 "아, 이런 느낌이구나" 하고 감을 잡을 수 있게 해줘서 정리해 봤어요.
핵심 직관들: KL 발산을 바라보는 여러 가지 렌즈
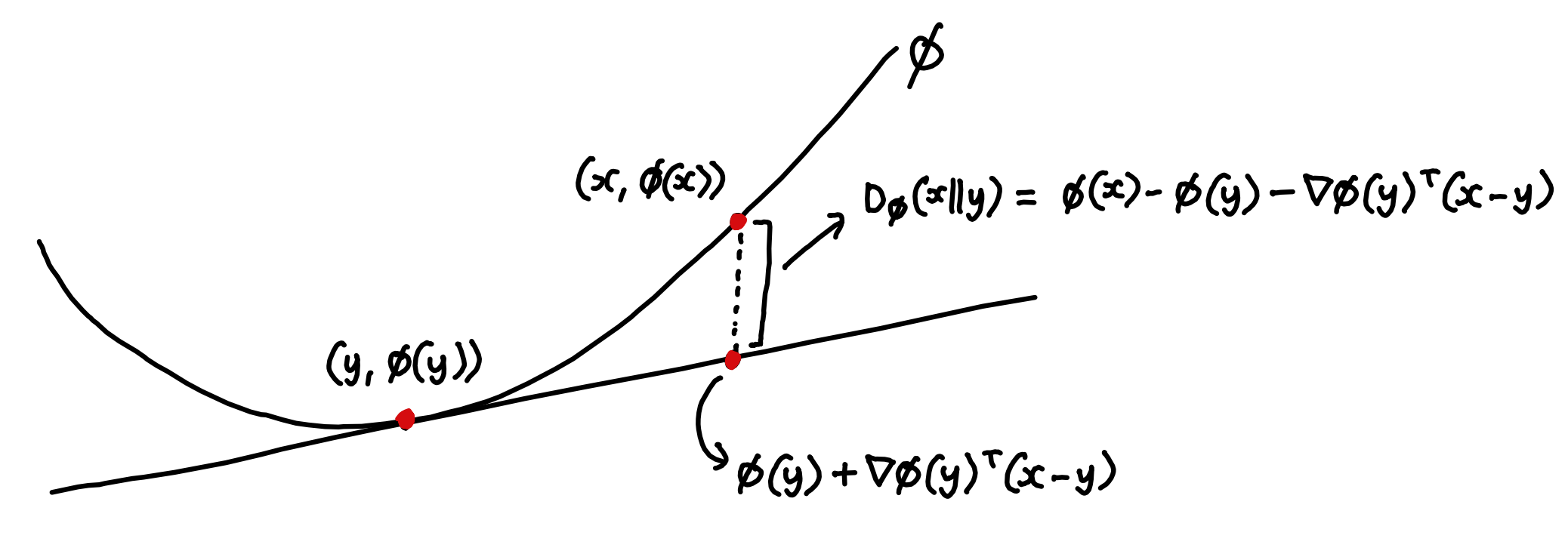
먼저 KL 발산이 뭐냐면, 쉽게 말해서 두 확률 분포가 얼마나 다른지를 재는 자예요. 예를 들어, 실제 데이터의 분포(P)와 우리 모델이 예측하는 분포(Q)가 있을 때, 이 둘이 얼마나 차이 나는지를 숫자 하나로 표현해 주는 거죠.
첫 번째 직관은 "놀라움의 차이"예요. 정보 이론에서 어떤 사건의 놀라움(surprise)은 그 사건이 일어날 확률이 낮을수록 커지거든요. KL 발산은 "Q 분포를 믿고 있었는데 실제로는 P 분포에서 데이터가 나올 때, 내가 느끼는 추가 놀라움의 평균"이라고 볼 수 있어요. 매일 맑을 거라고 생각했는데(Q) 실제로는 비가 자주 오는 지역(P)에 살고 있다면, 비 올 때마다 "어?" 하고 놀라잖아요. 그 놀라움의 누적이 KL 발산인 거예요.
두 번째는 "비효율적인 인코딩" 관점이에요. 데이터를 압축할 때 실제 분포 P에 맞춰서 코드를 설계하면 가장 효율적이거든요. 그런데 Q라는 잘못된 분포에 맞춰서 코드를 설계하면 비트가 낭비돼요. 이 낭비되는 비트의 평균이 바로 KL 발산이에요. 자주 쓰는 글자에 긴 코드를 할당하면 낭비가 생기는 것과 같은 원리죠.
세 번째는 "베이지안 업데이트의 크기"라는 관점인데요, 사전 분포(prior)에서 사후 분포(posterior)로 믿음을 업데이트할 때 얼마나 많이 바뀌었는지를 KL 발산으로 잴 수 있어요. 새로운 증거를 봤을 때 내 믿음이 크게 바뀌었다면 KL 발산이 크고, 별로 안 바뀌었다면 작은 거죠.
네 번째와 다섯 번째 직관은 각각 통계적 가설 검정과 모델 선택의 관점에서 바라보는 건데요. 두 분포를 구별하는 게 얼마나 쉬운지, 그리고 여러 모델 중에서 실제 데이터에 가장 가까운 모델을 고르는 기준으로 KL 발산이 자연스럽게 등장한다는 이야기예요.
여섯 번째는 "후회(regret)"의 관점이에요. 도박이나 투자에서 최적 전략 대비 내 전략이 얼마나 손해를 보는지를 재는 것과 연결되는데, 정보 이론적 후회가 결국 KL 발산과 같은 구조를 가진다는 거예요.
그리고 반쪽짜리 직관 하나는 KL 발산의 비대칭성에 관한 건데요. KL(P||Q)와 KL(Q||P)가 다르다는 점, 즉 "P 기준으로 Q를 평가"하는 것과 "Q 기준으로 P를 평가"하는 게 다르다는 특성을 다뤄요. 이건 실무에서도 정말 중요한 포인트거든요.
업계에서 KL 발산이 쓰이는 곳
요즘 가장 핫한 적용 사례는 역시 RLHF(인간 피드백 강화학습)예요. ChatGPT 같은 모델을 사람 취향에 맞게 튜닝할 때, 원래 모델에서 너무 멀어지지 않도록 KL 페널티를 걸거든요. 이때 KL 발산이 "원래 모델과 튜닝된 모델이 얼마나 달라졌는지"를 재는 역할을 해요. DPO(Direct Preference Optimization) 같은 최신 기법에서도 이 개념은 핵심이에요.
지식 증류에서도 마찬가지예요. 큰 모델(teacher)의 출력 분포를 작은 모델(student)이 따라하게 할 때, 두 분포의 차이를 KL 발산으로 측정하고 이걸 줄이는 방향으로 학습시키죠. 그 외에도 GAN 학습, 변분 추론, 이상 탐지 등 정말 다양한 곳에서 만나게 돼요.
한국 개발자에게 주는 시사점
사실 KL 발산은 ML 엔지니어라면 피할 수 없는 개념이에요. 특히 요즘 LLM 파인튜닝이나 경량화 작업을 하시는 분들이 많은데, KL 발산의 직관을 제대로 이해하고 있으면 하이퍼파라미터 튜닝할 때 "왜 이 값이 이렇게 나오지?"에 대한 감이 훨씬 좋아져요. 또 KL(P||Q)와 KL(Q||P) 중 어느 방향을 쓸지 선택하는 것도 실무에서 자주 마주치는 결정인데, 직관이 있으면 훨씬 합리적인 판단을 내릴 수 있거든요.
수식이 어렵다고 느끼셨던 분들은 위의 직관들 중 자기한테 와닿는 것 하나만 확실히 잡아도 큰 도움이 될 거예요.
정리
KL 발산은 결국 "내 모델이 현실에서 얼마나 벗어나 있는지를 재는 도구"예요. 여러분은 위의 직관 중 어떤 게 가장 와닿으셨나요? 실무에서 KL 발산을 쓸 때 겪었던 경험이 있다면 공유해 주세요!
🔗 출처: Hacker News
"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공