"모델을 더 크게" vs "계산을 더 많이", 어느 쪽이 정답일까요
요즘 AI 모델 얘기 들어보면 "파라미터(parameter)가 몇 천억 개"라는 말이 자주 나오죠. 파라미터라는 게 뭐냐면, 신경망 안에 있는 작은 다이얼들 같은 거예요. 이 다이얼을 잘 맞춰놔야 모델이 똑똑해지는데, 다이얼이 많을수록 더 복잡한 패턴을 배울 수 있어요. 그래서 한동안 업계는 "무조건 파라미터 많이!"를 외쳤어요. GPT-3가 1750억 개라느니, 어디는 1조 개라느니 하면서요.
그런데 메타(당시 페이스북) AI의 ParlAI 팀이 2021년에 던진 질문이 있어요. "잠깐, 파라미터를 늘리는 거랑 계산을 더 많이 하는 거, 둘 다 비용이 드는데, 같은 비용이면 어느 쪽이 더 이득일까?" 라는 질문이었죠. 이게 별것 아닌 것 같아도, 모델을 만드는 회사 입장에서는 GPU 청구서가 수십, 수백억 단위로 갈리는 문제예요.
두 가지 방법으로 모델을 "키우는" 방식
전통적으로 모델 성능을 올리는 방법은 두 가지예요. 하나는 그냥 "덴스(dense) 모델" 을 키우는 거예요. 모든 입력에 대해 모든 파라미터가 다 동작하는 방식이죠. 머리가 커지는 만큼 계산도 같이 늘어나요. 다른 하나는 "MoE(Mixture of Experts, 전문가 혼합)" 라는 방식인데, 이게 이 연구의 핵심이에요.
MoE를 쉽게 설명하면 이런 거예요. 큰 회사를 상상해보세요. 어떤 일이 들어왔을 때 모든 직원이 다 달라붙어서 처리하는 게 아니라, 그 일에 맞는 전문가 두세 명한테만 보내는 거죠. 회사에는 직원이 100명 있어도 한 건당 일하는 사람은 4명뿐이에요. 그러면 "회사 전체 인원(파라미터)"은 엄청 많지만, "실제로 한 건 처리에 드는 일손(계산)"은 적어지는 거예요. MoE 모델이 딱 이런 구조예요. 파라미터는 많이 가지고 있지만, 입력마다 그중 일부만 활성화돼요.
실험 결과는 좀 의외였어요
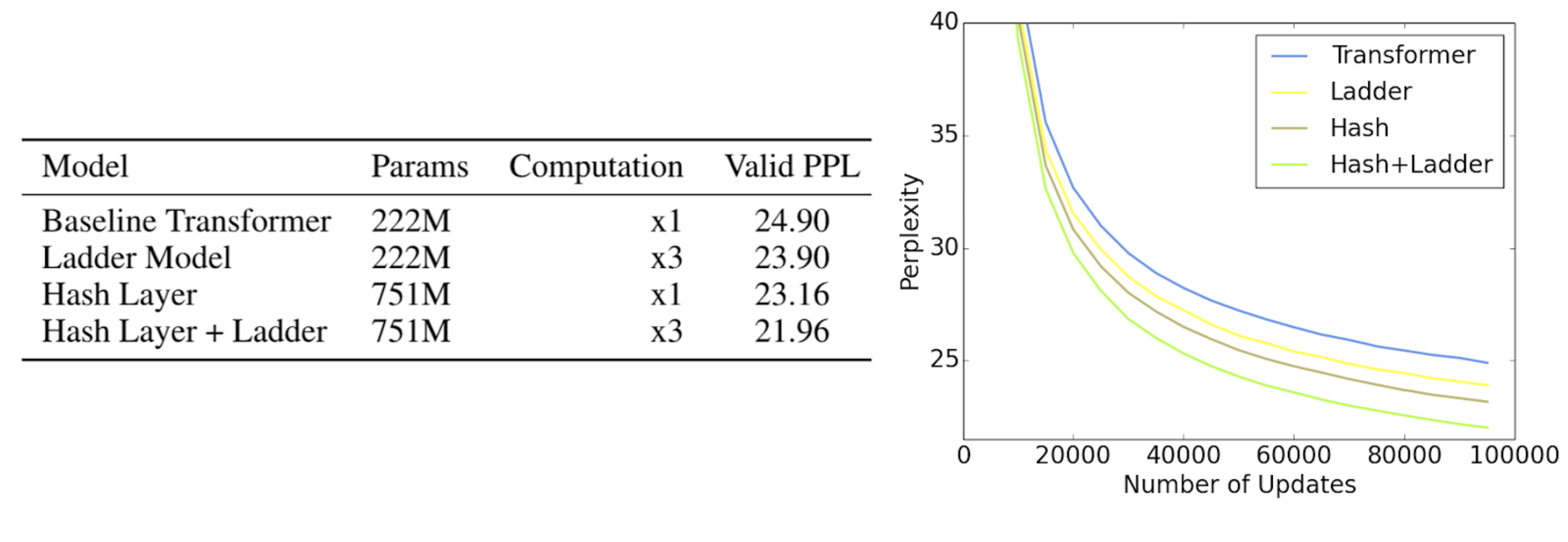
ParlAI 팀은 두 종류의 모델을 비교했어요. 같은 "훈련 비용(FLOPs, 즉 계산량)" 안에서 덴스 모델과 MoE 모델 중 누가 대화 품질이 더 좋은지를 본 거예요. 결과는 MoE가 같은 계산 비용으로 더 좋은 점수를 냈다 는 거였어요. 즉, 단순히 "파라미터를 곱해서 늘린 모델"보다, "전문가를 여러 명 두고 필요할 때만 쓰는 모델"이 훈련 효율 면에서 유리했다는 얘기예요.
다만 "공짜 점심"은 아니었어요. MoE 모델은 메모리를 엄청 많이 잡아먹어요. 100명짜리 회사 전체를 사무실에 앉혀놔야 하니까요, 비록 한 건당 4명만 일한다고 해도요. 그래서 추론(inference)할 때 GPU 메모리가 빵빵하지 않으면 돌리기가 어렵고, 분산 학습 셋업도 더 복잡해져요. 또 어떤 입력이 어느 전문가한테 가야 할지 결정하는 "라우터(router)"를 잘 학습시켜야 하는데, 이게 잘못되면 일부 전문가만 일하고 나머지는 놀거나, 부하가 한쪽으로 쏠리는 문제가 생겨요.
지금 와서 보면 이게 어디로 흘러갔냐면
2021년 시점의 이 논의가 지금 보면 정말 선견지명이었어요. 2024년 미스트랄(Mistral)에서 발표한 Mixtral 8x7B 가 MoE를 써서 화제가 됐고요, 이후 DeepSeek-V3, Qwen MoE, Grok 같은 큰 모델들이 줄줄이 MoE 구조를 채택했어요. 심지어 GPT-4도 MoE 기반이라는 게 거의 정설이에요. 즉 "덴스 모델 무한 확장" 시대가 한 번 꺾이고, "파라미터는 크게, 활성 계산은 적게"라는 방향으로 산업 전체가 움직인 거죠.
비교해서 보면, 구글의 Switch Transformer(2021) 와 GLaM 도 비슷한 시기에 MoE를 밀고 있었고요, 그 흐름의 한가운데에 ParlAI 팀의 이 논문이 있었어요. 그러니까 이 글이 단순히 "옛날 논문"이 아니라, 지금 우리가 쓰는 챗봇들의 설계 철학이 어떻게 정해졌는지를 보여주는 일종의 분기점인 셈이에요.
한국 개발자에게는 어떤 시사점이 있냐면
첫째, 모델을 직접 학습시키지 않더라도, 우리가 API로 쓰는 모델들이 어떤 트레이드오프 위에 서 있는지를 이해하면 선택이 쉬워져요. 예를 들어 "이 모델은 파라미터는 큰데 추론은 빠르다"는 설명이 나오면 "아, MoE구나" 하고 알아챌 수 있고, 그러면 메모리 비용이 비싸고 배치 크기 늘릴 때 주의가 필요하다는 것도 자연스럽게 짐작이 되죠.
둘째, 만약 사내에서 LLM을 자체적으로 파인튜닝하거나 호스팅하려고 한다면, MoE 모델은 "VRAM은 충분한데 처리량을 늘리고 싶다" 같은 상황에 잘 맞아요. 반대로 엣지 디바이스나 작은 GPU에서 돌리려면 같은 능력을 가진 덴스 모델이 더 합리적일 때가 많고요. 이 "파라미터 vs 계산"의 감각을 잡고 있으면 인프라 비용 의사결정이 훨씬 쉬워져요.
셋째, 이 연구는 "무지성으로 크게 만들면 다 해결"이라는 사고방식에 작은 균열을 낸 사례예요. 한국 스타트업이 자체 모델을 만들 때 "우리가 GPT랑 파라미터 경쟁할 순 없다"고 포기하기 쉬운데, 사실 구조를 잘 짜면 파라미터 수가 적어도 충분히 경쟁할 수 있는 길이 있다는 걸 보여주는 사례이기도 해요.
마무리
결국 이 연구가 우리에게 남긴 한 줄은 이거예요. "같은 비용이라면, 모든 파라미터를 매번 굴리는 것보다 필요한 전문가만 부르는 게 더 효율적이다." 너무 당연한 말 같지만, 이걸 수치로 증명하기 전까지 업계는 한참을 "덩치 키우기"에만 매달렸거든요.
여러분은 사내에서 LLM을 쓰실 때 모델 크기와 비용 사이에서 어떤 기준으로 선택하시나요? MoE 모델을 직접 다뤄본 경험이 있으시다면, 어떤 점이 가장 까다로웠는지 궁금해요.
🔗 출처: Hacker News


"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공