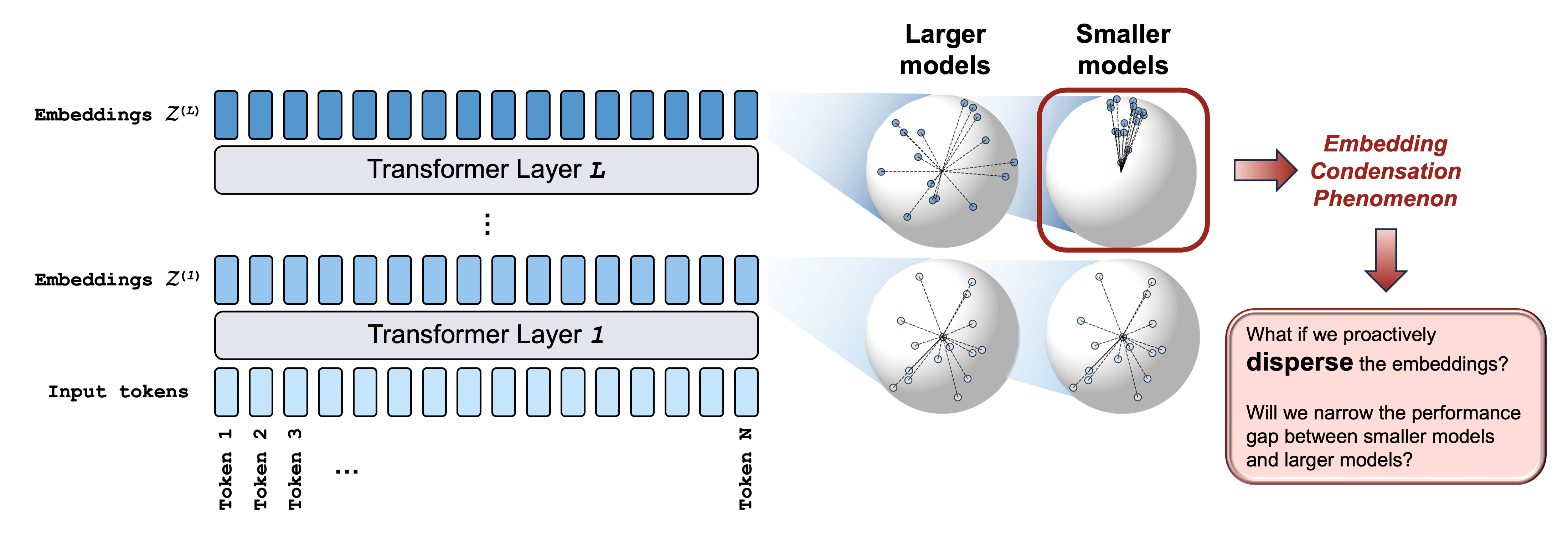
요즘 스마트폰이나 노트북에서 직접 돌아가는 온디바이스 AI 이야기가 정말 많이 나오는데요. 서버 없이 기기 안에서 모델을 돌리려면 크기가 작아야 하잖아요. 그런데 모델을 작게 만들면 성능이 뚝 떨어지는 게 늘 고민이었거든요. 최근 공개된 한 연구가 이 문제의 원인 하나를 콕 집어냈어요. 바로 “임베딩 응축(embedding condensation)”이라는 현상인데요. 더 반가운 건 이걸 아주 간단한 방법으로 고칠 수 있다는 거예요. 연구팀은 이걸 “공짜 점심(free lunch)”이라고 부를 정도예요.
임베딩이 뭉친다는 게 무슨 말이냐면
먼저 임베딩부터 짚고 갈게요. 언어모델은 단어(정확히는 토큰)를 숫자 벡터, 그러니까 고차원 공간의 좌표로 바꿔서 다뤄요. “고양이”와 “강아지”는 가까운 곳에, “고양이”와 “자동차”는 먼 곳에 놓이는 식이죠. 이 좌표들이 공간에 골고루 퍼져 있어야 모델이 단어들의 미묘한 차이를 구분할 수 있거든요.
그런데 연구팀이 작은 모델들의 내부를 들여다봤더니, 토큰 표현들이 넓은 공간을 놔두고 좁은 원뿔 모양 영역에 다닥다닥 몰려 있었어요. 얼마나 심하냐면, 파라미터 1,400만~1억 2,500만 개짜리 모델에서는 마지막 레이어 토큰 표현들의 평균 코사인 유사도(두 벡터가 얼마나 같은 방향을 보는지 재는 값인데, 1이면 완전히 같은 방향이에요)가 0.6~0.8까지 올라갔대요. 서로 다른 단어들인데 모델 눈에는 거의 비슷비슷하게 보인다는 뜻이에요. 반면 10억 파라미터가 넘는 큰 모델들은 자연스럽게 표현이 넓게 퍼져 있었고요. 그리고 이 뭉침이 심할수록 퍼플렉시티(모델이 다음 단어를 얼마나 못 맞히는지 나타내는 지표로, 낮을수록 좋아요)도 나쁘고 벤치마크 점수도 낮았어요. 뭉침 자체가 성능 저하와 같이 움직인다는 거죠.
해법은 의외로 간단해요: 분산 손실
연구팀이 제안한 해법이 분산 손실(dispersion loss)이에요. 학습할 때 토큰 표현들끼리 코사인 유사도가 높으면 벌점을 주는 보조 목적함수를 하나 추가하는 건데요. 쉽게 말해 “너희 너무 붙어 있지 말고 좀 떨어져!”라고 계속 밀어내 주는 거예요. 대조 학습(contrastive learning)에서 표현을 구(hypersphere) 위에 고르게 펴주는 균일성(uniformity) 손실에서 아이디어를 가져왔다고 해요.
수식으로 쓰면 전체 손실은 L = L_LM + λ·L_dispersion 형태예요. 기존의 다음 토큰 예측 손실에 분산 손실을 λ라는 가중치로 섞는 거죠. 재미있는 건 모든 레이어에 걸 필요도 없이 마지막 레이어에만 적용해도 효과가 거의 같았다는 점이에요. 추가 연산 비용도 몇 퍼센트 수준이라 사실상 공짜에 가깝고요.
결과도 꽤 인상적이에요. 1,400만~3억 5,000만 파라미터 규모의 모델들에서 퍼플렉시티가 상대적으로 3~8% 개선됐고, LAMBADA, HellaSwag, PIQA, WinoGrande, ARC-easy 같은 제로샷 벤치마크 점수도 일관되게 올라갔어요. 특히 모델이 작을수록 효과가 컸고, 10억 파라미터 이상에서는 효과가 거의 사라졌는데요. 큰 모델은 애초에 표현이 잘 퍼져 있으니 당연한 결과죠. 다만 λ를 너무 키우면 본래의 언어모델 학습을 방해해서, 적당한 세기가 중요하다는 것도 확인했어요.
사실 오래된 문제의 새로운 해석이에요
이 현상 자체가 완전히 새로운 건 아니에요. 학계에서는 예전부터 “표현 퇴화(representation degeneration)”나 “이방성(anisotropy)” 문제라고 불러왔거든요. 임베딩이 공간에 고루 퍼지지 못하고 한쪽으로 쏠리는 현상인데, BERT나 GPT-2 시절부터 문장 임베딩 품질을 갉아먹는 주범으로 지목됐어요. 이번 연구의 기여는 이 문제를 “모델 크기”라는 축으로 다시 조명했다는 데 있어요. 작은 모델일수록 뭉침이 심해진다는 걸 체계적으로 보여주고, 값싼 처방까지 검증한 거죠. 요즘 구글 Gemma, 마이크로소프트 Phi, 허깅페이스 SmolLM처럼 소형 모델 경쟁이 뜨거운데, 이 흐름과 딱 맞아떨어지는 연구예요.
우리에게 주는 시사점
소형 모델을 직접 사전학습하거나 도메인 특화 모델을 만들어보는 팀이라면 바로 시도해볼 만해요. 구현이 정말 간단하거든요. 배치 안 표현들의 쌍별 코사인 유사도를 계산해서 손실에 더하면 끝이에요. 굳이 학습을 안 하더라도, 지금 쓰는 모델의 마지막 레이어 표현들 평균 코사인 유사도를 재보는 것만으로 모델 상태를 진단하는 좋은 도구가 되고요. 임베딩 기반 검색이나 RAG를 만들 때 작은 임베딩 모델의 검색 품질이 이상하다면, 이 뭉침 현상을 의심해볼 수도 있어요.
정리하면, “작은 모델의 임베딩은 뭉치고, 살짝 밀어서 펴주면 공짜로 성능이 오른다”는 이야기예요. 여러분은 소형 모델을 다루면서 이런 표현 붕괴 현상을 겪어보신 적 있나요? 온디바이스 모델 만들 때 쓰는 나만의 트릭이 있다면 같이 나눠주세요.
🔗 출처: Hacker News