LLM은 왜 그렇게 느릴까?
ChatGPT나 Claude 쓰다 보면 글자가 한 글자씩 또르륵 나오는 거 보셨죠? 그게 그냥 연출이 아니라, 실제로 LLM이 토큰 하나를 만들 때마다 모델 전체를 한 번씩 통과시키는 구조라서 그래요. 70B(700억 파라미터) 모델이라면 토큰 하나 만들 때마다 700억 개 가중치를 다 거쳐야 한다는 뜻이에요. GPU 메모리에서 가중치를 읽어오는 시간이 병목이라 무지막지하게 느리고 비싸요.
그래서 몇 년 전부터 speculative decoding(추측 디코딩)이라는 기법이 주목받고 있어요. 이게 뭐냐면, 작고 빠른 "draft 모델"이 먼저 여러 토큰을 미리 추측해서 만들어두고, 큰 메인 모델은 그걸 한 번에 검증만 하는 방식이에요. 검증은 forward pass 한 번으로 여러 토큰을 동시에 확인할 수 있거든요. 작은 모델이 맞게 예측한 토큰들은 그대로 채택하고, 틀린 부분부터는 큰 모델 결과로 교체해요. 핵심은 출력 분포가 원본과 수학적으로 동일하다는 점이에요. 빨라지지만 품질은 그대로인 거죠.
Orthrus가 등장했어요
최근 공개된 Orthrus-Qwen3 프로젝트가 이 분야에서 또 한 번 도약을 보여줬어요. Qwen3(알리바바가 만든 오픈소스 LLM 시리즈예요) 위에서 작동하는데, forward pass 한 번당 최대 7.8배의 토큰을 뽑아낼 수 있다고 해요. 그러면서도 출력 분포는 원본 Qwen3와 완전히 똑같아요. 이게 왜 대단하냐면, 기존 speculative decoding 기법들은 보통 2~3배 정도의 가속이 일반적이었거든요. Medusa, EAGLE, Lookahead 같은 유명한 기법들도 대개 그 범위였어요.
Orthrus라는 이름은 그리스 신화에 나오는 머리 둘 달린 개에서 따왔어요. 의미심장하죠. 메인 모델과 draft 모듈이 함께 움직이면서, 한쪽이 빠르게 "내달리고" 다른 쪽이 검증한다는 구조를 상징하는 것 같아요.
어떻게 그렇게 빠르게?
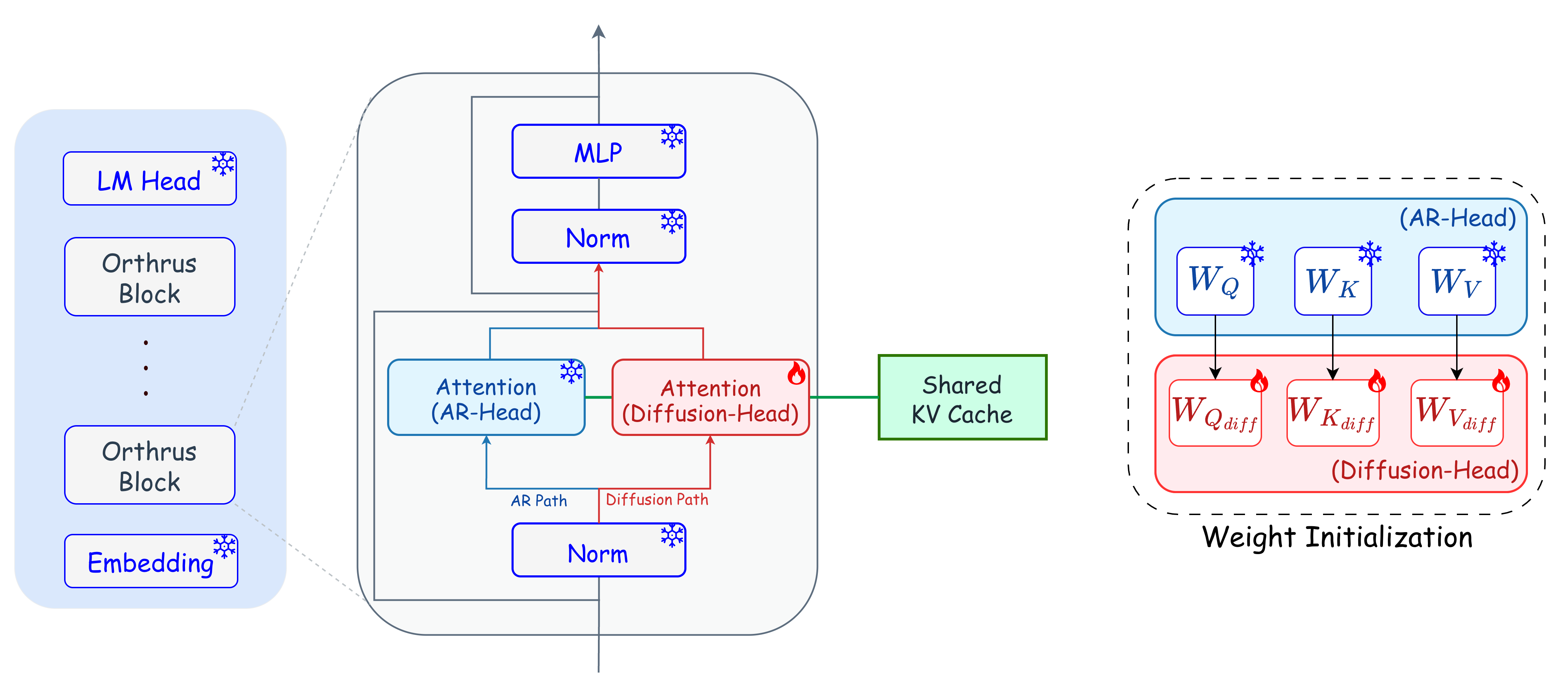
구체적인 기법은 EAGLE 계열의 발전형으로 보이는데요. 핵심 아이디어를 풀어서 설명하면 이래요. 기존 방식은 draft 모델이 큰 모델과 별개로 따로 학습된 작은 모델이었어요. 그러다 보니 큰 모델이 "뭘 생각하는지"에 대한 정보를 잘 못 받았고, 예측 적중률에 한계가 있었죠.
EAGLE 같은 최신 기법은 큰 모델의 내부 hidden state(중간 계산 결과)를 draft 모듈에 입력으로 넣어주는 방식이에요. 큰 모델이 토큰 하나를 만들 때 마지막 레이어 직전의 "속마음"이 있는데, 그걸 draft 모듈한테 보여주면서 "이 다음에 뭐가 나올지 맞춰봐"라고 시키는 거예요. 그러면 적중률이 훨씬 높아져요.
Orthrus는 여기서 한 발 더 나아간 것으로 보여요. 트리 형태로 여러 후보를 동시에 탐색하는 tree attention 기법, 그리고 더 정교하게 학습된 가벼운 draft 헤드를 결합한 것 같아요. 7.8배라는 수치는 단일 토큰이 아니라 트리 전체를 한 번에 검증할 때 평균적으로 채택되는 토큰 수를 의미할 거예요. 코드 같은 예측 가능한 패턴에서는 적중률이 높아져서 더 큰 속도 향상이 나오고, 창의적 글쓰기처럼 분기가 많은 경우엔 좀 떨어질 수 있어요.
비슷한 기술들과 비교해보면
speculative decoding 영역엔 이미 많은 경쟁자가 있어요. Medusa는 메인 모델에 여러 개의 추가 헤드를 붙여서 동시에 여러 위치의 토큰을 예측하는 방식이고, EAGLE과 EAGLE-2는 hidden state 기반 draft로 적중률을 높였어요. Lookahead Decoding은 별도 draft 모델 없이 메인 모델 자체로 추측-검증 사이클을 돌리는 방식이고, vLLM 같은 추론 엔진엔 이미 여러 기법이 내장돼 있어요.
Orthrus의 의미는 "오픈소스 모델에서도 상용 API에 견줄 만한 추론 속도를 낼 수 있다"는 걸 보여줬다는 점이에요. Qwen3는 오픈웨이트 모델 중 성능이 매우 우수한 편이고, 여기에 7배 가까운 가속이 붙으면 자체 호스팅의 경제성이 크게 달라져요. 그동안 "GPT-4급 품질을 자체 서버에서 돌리고 싶지만 너무 느리고 비싸다"는 게 자체 호스팅의 가장 큰 장벽이었는데, 이 장벽이 점점 낮아지고 있는 거죠.
한국 개발자에게는?
자체 LLM 인프라를 운영하거나 그럴 계획이 있는 팀이라면 꽤 직접적으로 관심 가져볼 만해요. 특히 on-prem(자사 서버)에서 LLM을 돌려야 하는 금융권, 공공, 의료 도메인에서는 OpenAI나 Anthropic API를 쓸 수 없으니까 자체 호스팅이 강제되거든요. 이런 환경에서 같은 GPU로 7배 많은 요청을 처리할 수 있다면 그건 곧 인프라 비용이 1/7로 줄어든다는 의미니까요.
다만 실무에 도입할 때 주의할 점도 있어요. "최대 7.8배"라는 건 가장 좋은 조건에서의 수치예요. 실제 워크로드, 특히 한국어 같은 다국어 환경에서는 영어 벤치마크보다 적중률이 낮아질 수 있어요. 또 배치 크기가 커지면 speculative decoding의 이점이 줄어드는 경향이 있어서, 동시 요청이 많은 서비스에선 효과가 제한적일 수 있어요. 직접 자기 데이터로 벤치마크 해보는 게 필수입니다.
또 하나, 이런 기법들은 출력 분포가 동일하다는 게 보장되니까 "속도와 품질 트레이드오프" 고민 없이 도입할 수 있다는 게 매력이에요. 기존 모델을 그대로 두고 추론 레이어만 갈아끼우는 식의 통합이 가능하거든요.
마무리
LLM 추론 최적화는 모델을 더 똑똑하게 만드는 것만큼이나 산업적 임팩트가 큰 영역이에요. Orthrus 같은 프로젝트가 보여주는 건 "같은 모델, 같은 GPU로 몇 배의 처리량"이라는 게 점점 현실이 되고 있다는 사실이죠.
여러분은 자체 LLM 호스팅 해보신 경험 있으세요? 어떤 추론 엔진(vLLM, TGI, SGLang 등)을 쓰고 계신지, speculative decoding 적용해본 경험이 있다면 어떤 워크로드에서 효과가 좋았는지 공유해주시면 다른 분들께도 도움이 될 것 같아요.
🔗 출처: Hacker News
"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공