들어가며
ChatGPT 같은 걸 매일 쓰면서도 "얘는 도대체 어떻게 말을 만들어내는 거지?" 하고 한 번쯤 궁금했을 거예요. 막연히 "엄청 똑똑한 AI"라고만 알고 넘어가기엔 좀 아쉽잖아요. 그래서 오늘은 LLM(대형 언어 모델, Large Language Model)이 실제로 어떻게 동작하는지를 주니어도 이해할 수 있게 한 단계씩 풀어볼게요. 사실 알고 보면 핵심 아이디어는 의외로 단순하거든요.
결국 하는 일은 '다음 단어 맞히기'
충격적일 수 있는데, LLM이 하는 일의 본질은 딱 하나예요. "지금까지 나온 글을 보고, 그 다음에 올 가장 그럴듯한 단어를 예측하는 것." 그게 전부입니다.
예를 들어 "오늘 날씨가 정말" 까지 입력하면, 모델은 그 다음에 "좋다", "덥다", "춥다" 같은 후보들 중에서 확률이 가장 높은 걸 고르는 거예요. 그리고 그 단어를 붙인 다음, 또 그 뒤에 올 단어를 예측하고, 또 예측하고… 이걸 계속 반복하면서 문장이 줄줄 만들어집니다. 마치 휴대폰 키보드의 자동완성을 어마어마하게 똑똑하게 만든 버전이라고 생각하면 비슷해요.
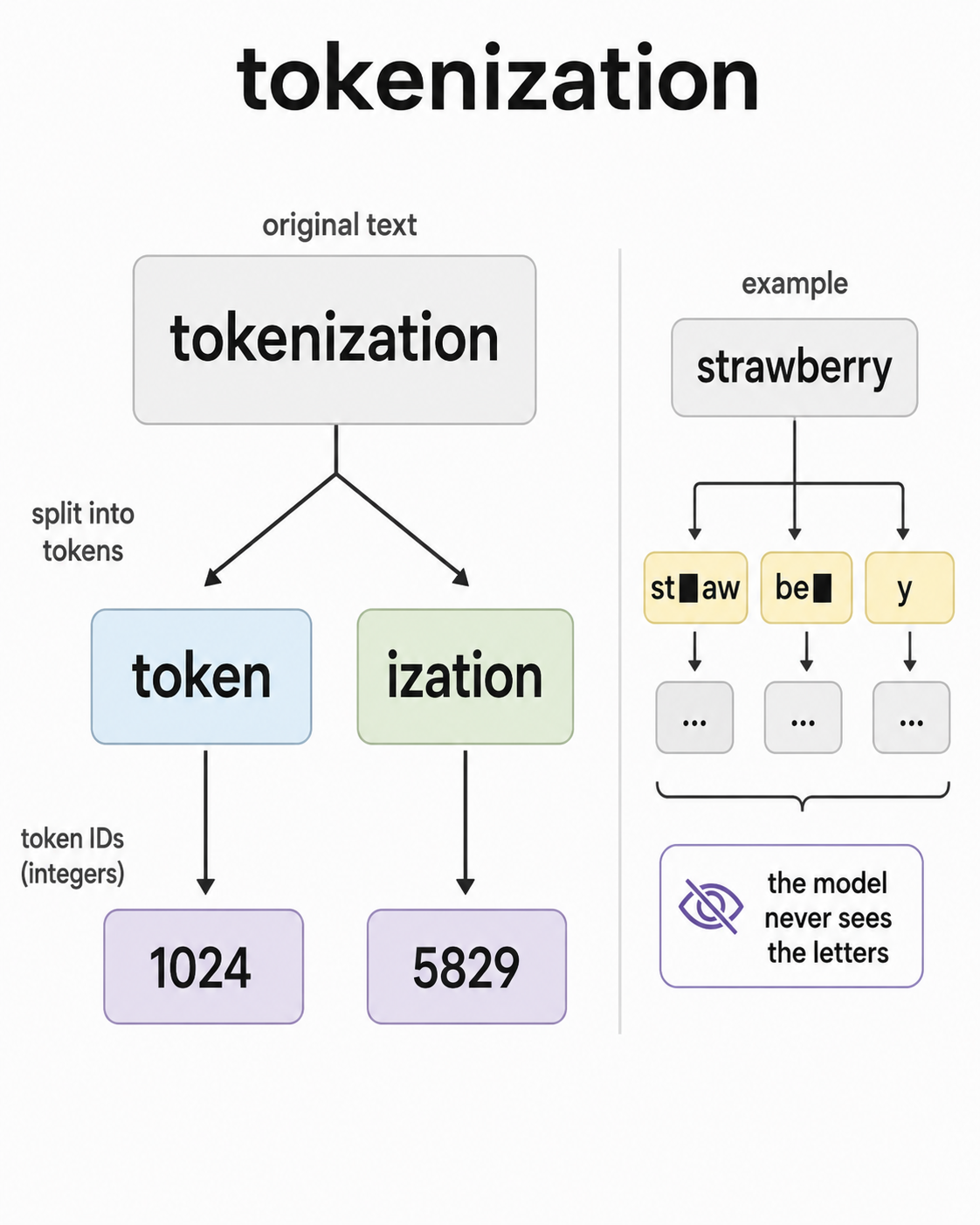
단어를 숫자로 바꾸는 과정
그런데 컴퓨터는 글자를 그대로 이해하지 못하거든요. 숫자만 다룰 줄 알아요. 그래서 먼저 글을 잘게 쪼개는데, 이 조각을 토큰(token) 이라고 불러요. 토큰은 단어 하나일 수도, '먹었어요' 같은 단어의 일부일 수도 있어요. 영어로 치면 'unbelievable'이 'un', 'believ', 'able' 식으로 나뉘는 거죠.
그리고 각 토큰을 임베딩(embedding) 이라는 숫자 묶음(벡터)으로 바꿔요. 이게 핵심인데요, 단순히 번호를 매기는 게 아니라 의미가 비슷한 단어는 숫자상으로도 가까운 위치에 놓이게 만듭니다. 그래서 '왕'과 '여왕', '서울'과 '부산'처럼 관련 있는 단어들이 좌표 공간에서 서로 이웃하게 돼요. 모델은 이 숫자 좌표를 가지고 의미를 다루는 거예요.
핵심 비밀, '어텐션'
LLM을 진짜 LLM답게 만든 결정적 기술이 바로 어텐션(attention, 주의 집중) 이에요. 이게 뭐냐면, 문장 속에서 "어떤 단어가 어떤 단어를 더 주의 깊게 봐야 하는지"를 계산하는 장치예요.
예를 들어 "그 강아지는 배가 고파서 그것을 먹었다"라는 문장에서 '그것'이 뭘 가리키는지 알려면 앞쪽 단어들과의 관계를 따져야 하잖아요. 어텐션은 각 단어가 다른 모든 단어를 둘러보면서 "넌 나랑 얼마나 관련 있어?" 하고 가중치를 매겨요. 덕분에 멀리 떨어진 단어 사이의 연결까지 포착할 수 있게 됐죠. 이 어텐션을 여러 층으로 쌓아 올린 구조가 그 유명한 트랜스포머(Transformer) 이고, 오늘날 거의 모든 LLM이 이 구조를 씁니다.
어떻게 똑똑해지나
이 모델은 인터넷의 방대한 텍스트를 읽으면서 훈련돼요. 방식은 간단해요. 문장의 일부를 가리고 "다음 단어 뭐게?" 하고 맞혀보게 한 다음, 틀리면 내부의 수많은 숫자(파라미터, parameter)를 아주 조금씩 조정합니다. 이걸 수십억, 수조 번 반복하다 보면 어느새 문법도, 상식도, 코드 작성법까지도 그 숫자들 속에 녹아들게 돼요. 누가 "이건 명사야, 이건 동사야" 하고 가르쳐준 게 아니라, 그냥 다음 단어 맞히기를 무진장 반복하다 보니 저절로 언어의 규칙을 터득한 거예요. 신기하죠?
그래서 왜 알아야 하냐면
이 원리를 알면 LLM을 훨씬 잘 다룰 수 있어요. "얘는 진짜 이해하는 게 아니라 확률적으로 그럴듯한 단어를 잇는다"는 걸 알면, 가끔 자신만만하게 틀린 답(이른바 환각, hallucination)을 내놓는 이유도 납득이 가거든요. 사실을 검증하는 게 아니라 '그럴듯함'을 좇는 구조라서 그래요. 또 프롬프트를 잘 써야 하는 이유, 맥락(context)을 충분히 줘야 답이 좋아지는 이유도 어텐션 구조를 떠올리면 자연스럽게 이해돼요.
마무리
정리하면 LLM은 '단어를 숫자로 바꾸고 → 어텐션으로 관계를 따진 뒤 → 다음 단어를 확률로 예측하는' 거대한 자동완성 기계예요. 마법이 아니라 잘 설계된 수학이라는 걸 알고 나면, 오히려 더 영리하게 활용할 수 있게 됩니다.
여러분은 LLM의 동작 원리를 알고 나서 사용하는 방식이 달라진 경험이 있으세요? '확률 기계'라는 본질을 알게 된 지금, AI를 어디까지 믿고 어디서부터 의심해야 한다고 생각하시는지 의견이 궁금해요.
🔗 출처: Hacker News
"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공