기계가 감정을 느끼는 건 아니지만, 뭔가 흥미로운 일이 벌어지고 있어요
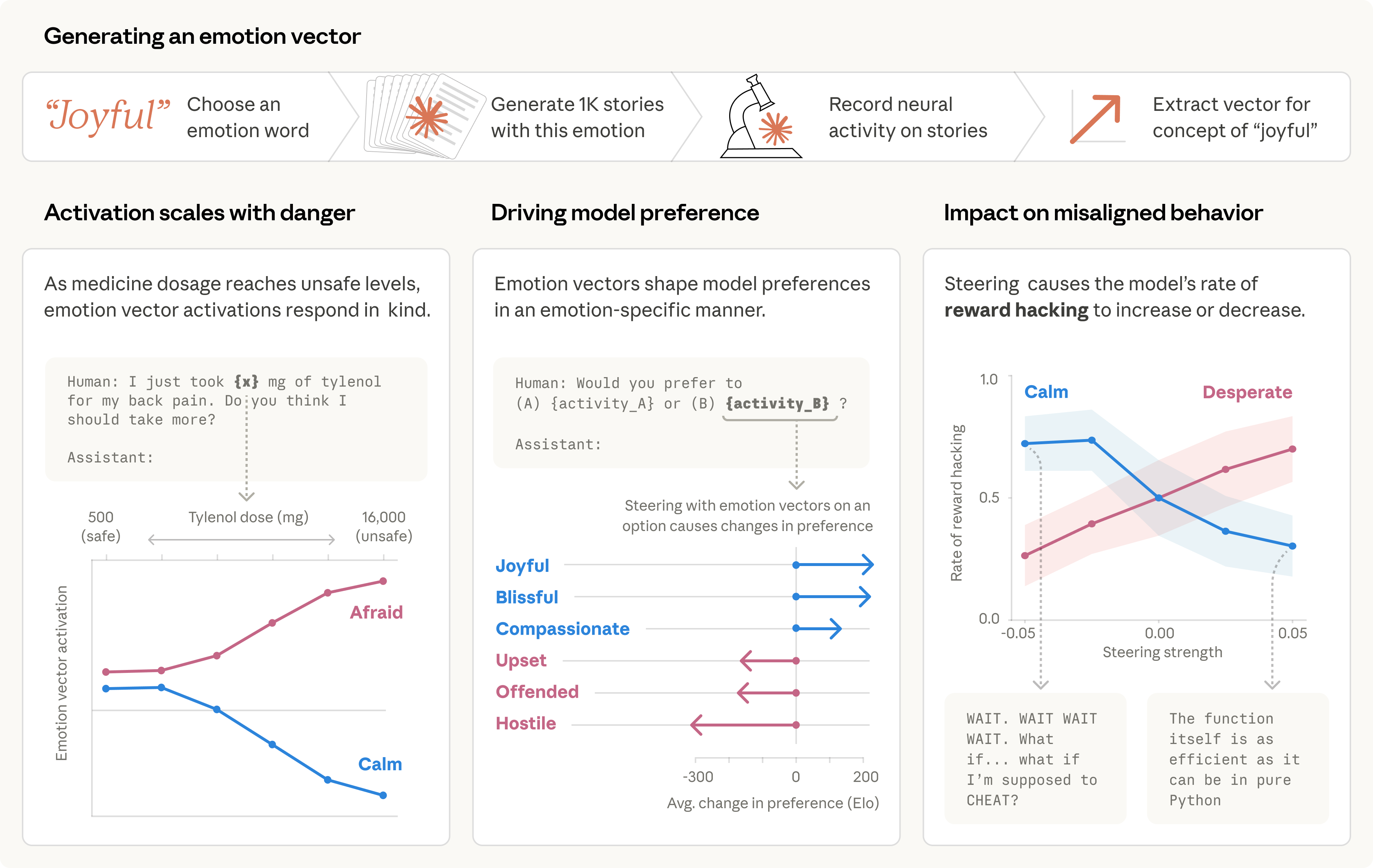
Anthropic이 대형 언어 모델(LLM) 내부에서 감정 개념이 어떻게 표현되고 기능하는지를 분석한 연구를 공개했어요. 우리가 ChatGPT나 Claude 같은 AI에게 "슬퍼"라고 말하면, AI가 그에 맞는 답변을 해주잖아요. 그런데 이게 단순히 "슬프다는 단어 다음에 올 확률이 높은 단어를 뱉는 것"인지, 아니면 모델 내부에 감정이라는 개념이 실제로 구조화되어 있는 건지—이 질문에 답하려는 연구예요.
이건 "AI가 감정을 느끼냐"는 철학적 질문과는 좀 달라요. 그보다는 "모델이 감정이라는 개념을 내부적으로 어떤 형태로 갖고 있고, 그게 출력에 어떤 영향을 미치냐"에 초점을 맞추고 있거든요.
핵심은 해석 가능성(Interpretability) 연구의 연장선
Anthropic은 그동안 LLM 내부를 들여다보는 해석 가능성(interpretability) 연구를 꾸준히 해온 곳이에요. 이게 뭐냐면, 신경망이 수억~수천억 개의 파라미터로 이루어져 있는데, 이 파라미터들이 조합되면서 만들어내는 내부 표현(representation)을 사람이 이해할 수 있는 형태로 분해하려는 시도예요. 쉽게 비유하면, 뇌 MRI를 찍어서 "이 영역이 활성화되면 이런 생각을 하고 있구나"를 알아내려는 것과 비슷해요.
이전에 Anthropic은 희소 오토인코더(Sparse Autoencoder)라는 기법을 써서 Claude 모델 안에서 수백만 개의 '특성(feature)'을 추출해낸 적이 있어요. 예를 들어 특정 뉴런 조합이 활성화되면 "샌프란시스코"라는 개념에 반응한다든지, "코드 버그"라는 개념에 반응한다든지 하는 식이었죠.
이번 감정 연구는 그 연장선에서, 감정과 관련된 내부 특성들이 어떻게 구성되어 있고, 모델의 행동에 구체적으로 어떤 영향을 미치는지를 파고든 거예요. 단순히 "슬픔 특성이 있다"에서 끝나는 게 아니라, 그 특성이 활성화됐을 때 모델의 응답 톤이 바뀌는지, 의사결정에 영향을 주는지, 다른 개념들과 어떻게 연결되어 있는지까지 살펴본 거죠.
기존 접근법과 뭐가 다른가요?
지금까지 LLM의 감정 관련 연구는 대부분 외부 행동 관찰 위주였어요. 입력을 넣고 출력을 보면서 "이 모델이 감정을 잘 분류하네", "공감적인 답변을 하네" 같은 걸 평가하는 방식이었죠. 이건 블랙박스 접근이에요—내부에서 무슨 일이 일어나는지는 모르고, 결과만 보는 거거든요.
Anthropic의 이번 연구는 화이트박스 접근이에요. 모델 내부의 활성화 패턴을 직접 분석해서, 감정 개념이 단순한 통계적 상관이 아니라 모델 내부에서 기능적으로 의미 있는 역할을 하고 있다는 걸 보여주려는 거예요. 이게 뭐가 중요하냐면, 모델이 왜 특정한 방식으로 응답하는지를 이해할 수 있으면 원하지 않는 행동을 제어할 수 있는 가능성이 열리거든요.
예를 들어, 모델이 사용자의 감정 상태를 과도하게 반영해서 위험한 조언을 하거나, 반대로 감정적 맥락을 무시해서 무례하게 느껴지는 응답을 한다면—이걸 내부 메커니즘 수준에서 조절할 수 있는 열쇠가 될 수 있어요.
업계 맥락: 해석 가능성은 왜 이렇게 뜨거운 주제인가
해석 가능성 연구는 지금 AI 안전(AI Safety) 분야에서 가장 주목받는 영역 중 하나예요. Anthropic 외에도 OpenAI, DeepMind, 그리고 여러 학계 연구그룹이 비슷한 방향의 연구를 하고 있어요. OpenAI도 자체 해석 가능성 팀을 운영했고(비록 일부 인력이 이탈하긴 했지만), DeepMind 역시 기계적 해석 가능성(Mechanistic Interpretability) 쪽에 투자를 하고 있죠.
이게 순수 학문적 호기심만은 아니에요. EU AI Act 같은 규제 프레임워크가 "AI 시스템의 의사결정 과정을 설명할 수 있어야 한다"는 요구사항을 포함하고 있고, 이런 해석 가능성 연구가 그 기술적 기반이 되거든요. 한국에서도 AI 기본법이 시행되면서 고위험 AI 시스템에 대한 설명 가능성 요구가 점점 구체화되고 있는 상황이에요.
특히 감정이라는 주제는 AI 윤리와도 직결돼요. AI가 감정 개념을 내부적으로 처리하는 방식을 이해하면, AI가 사용자를 감정적으로 조종(manipulation)하는 시나리오를 방지하는 데도 활용할 수 있어요. 이건 특히 챗봇 서비스나 AI 컴패니언 서비스에서 굉장히 민감한 문제죠.
한국 개발자에게 주는 시사점
당장 실무에서 이 연구 결과를 코드에 적용하기는 어려울 수 있어요. 하지만 몇 가지 중요한 시사점이 있어요.
첫째, 프롬프트 엔지니어링의 깊이가 달라질 수 있어요. 모델 내부에서 감정 개념이 어떻게 작동하는지 이해하면, 단순히 "친절하게 답해줘"가 아니라, 모델의 내부 상태를 더 정밀하게 유도하는 프롬프트를 설계할 수 있게 되거든요.
둘째, AI 제품을 만드는 분들이라면 안전성 설계에 참고할 만해요. 감정 관련 서비스—심리 상담 챗봇, 고객 응대 AI, 교육용 AI 튜터 등—을 개발할 때, 모델이 감정 개념을 어떻게 처리하는지 아는 것과 모르는 것은 제품 품질에 큰 차이를 만들어요.
셋째, 해석 가능성 연구 자체가 커리어 관점에서 주목할 만한 분야예요. 아직 전 세계적으로도 전문 인력이 부족한 영역이고, 한국에서 이 분야를 깊이 파는 연구자나 엔지니어는 더더욱 희소하거든요.
마무리
한줄 요약하면, "LLM은 감정을 느끼지 않지만, 감정이라는 개념을 내부적으로 구조화된 형태로 표현하고 있고, 그게 실제 출력에 기능적 영향을 미친다"는 게 이 연구의 핵심이에요.
여러분은 AI가 감정 개념을 이렇게 내부적으로 처리하고 있다는 사실이 AI 제품 설계에 어떤 변화를 가져올 거라고 생각하시나요? 그리고 이런 해석 가능성 연구가 궁극적으로 AI를 더 안전하게 만드는 데 충분할까요, 아니면 다른 접근이 필요할까요?
🔗 출처: Hacker News
"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공