LLM의 고질적 문제, 긴 컨텍스트 처리 비용
요즘 LLM(대규모 언어 모델)을 써보면 컨텍스트 윈도우가 점점 길어지고 있죠. GPT-4o는 128K 토큰, Claude는 200K 토큰까지 지원하고, Gemini는 백만 토큰을 넘기기도 해요. 그런데 컨텍스트가 길어지면 한 가지 심각한 문제가 생기는데요, 바로 어텐션(Attention) 연산 비용이 기하급수적으로 증가한다는 거예요.
이게 뭐냐면, 트랜스포머 아키텍처에서 어텐션이라는 건 입력된 모든 토큰이 다른 모든 토큰과의 관계를 계산하는 과정이에요. 마치 교실에서 30명의 학생이 각각 다른 29명 모두와 악수를 해야 하는 것처럼요. 학생이 30명이면 435번의 악수로 끝나지만, 300명이면 44,850번이 돼요. 토큰 수가 늘어나면 연산량은 제곱으로 늘어나는 거죠. 이걸 O(n²) 복잡도라고 해요. 그래서 긴 문맥을 처리할 때 GPU 메모리를 엄청나게 잡아먹고, 추론 속도도 느려지게 되는 거예요.
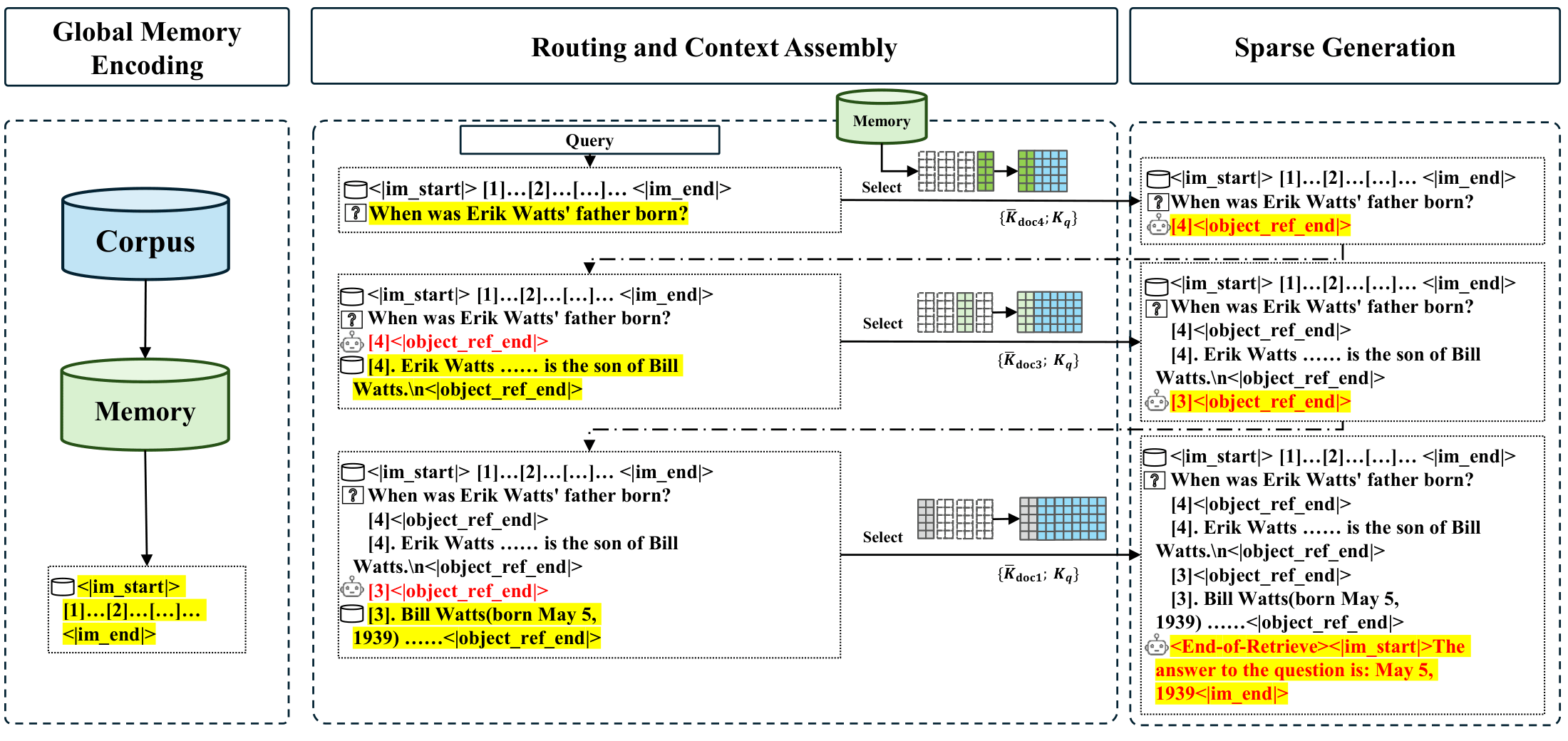
Memory Sparse Attention(MSA)는 EverMind AI에서 공개한 오픈소스 프로젝트로, 바로 이 어텐션 연산의 메모리 사용량을 획기적으로 줄이는 기법이에요.
MSA의 핵심 아이디어
MSA의 기본 발상은 단순하면서도 영리해요. 어텐션을 계산할 때 모든 토큰 쌍을 다 보지 않아도 된다는 거예요. 실제로 어텐션 스코어를 분석해보면, 대부분의 토큰은 소수의 다른 토큰에만 높은 어텐션을 갖고 나머지는 거의 0에 가까워요. 그러니까 어차피 무시될 연산을 굳이 할 필요가 없다는 아이디어에서 출발하는 거죠.
기존의 스파스 어텐션(Sparse Attention) 기법들도 비슷한 아이디어를 쓰는데, MSA가 차별화되는 지점은 메모리 효율성에 초점을 맞췄다는 거예요. 단순히 연산을 건너뛰는 게 아니라, GPU 메모리에 올려야 하는 KV 캐시(Key-Value Cache)의 크기 자체를 줄여요. KV 캐시가 뭐냐면, 이전 토큰들의 정보를 저장해두는 일종의 메모장인데요, 컨텍스트가 길어지면 이 메모장이 GPU 메모리의 대부분을 차지하게 돼요. MSA는 이 메모장에서 "정말 중요한 내용만" 남기고 나머지를 정리하는 방식으로 메모리를 절약해요.
구체적으로는 어텐션 패턴을 분석해서 중요도가 낮은 토큰의 KV 엔트리를 동적으로 제거(eviction)하거나 압축하는 전략을 사용해요. 이렇게 하면 전체 시퀀스 길이에 비례하는 메모리 대신, 실제로 의미 있는 토큰 수에 비례하는 메모리만 사용할 수 있게 되는 거예요.
비슷한 기술들과의 비교
긴 컨텍스트를 효율적으로 처리하려는 시도는 최근 몇 년간 활발하게 이루어지고 있어요. 몇 가지 대표적인 접근법을 비교해볼게요.
FlashAttention은 어텐션 연산 자체를 GPU 하드웨어에 최적화해서 속도를 높이는 기법인데요, 이건 연산 방식은 동일하되 하드웨어 활용을 극대화하는 거라 MSA와는 접근이 달라요. 실제로 MSA와 FlashAttention은 상호 보완적으로 함께 쓸 수 있어요.
Sliding Window Attention은 각 토큰이 주변 N개의 토큰만 보는 방식이에요. Mistral 모델이 이 방식을 사용하는데, 단점은 먼 거리에 있는 토큰과의 관계를 놓칠 수 있다는 거예요. MSA는 거리와 무관하게 중요도 기반으로 토큰을 선택하기 때문에 이런 한계가 적어요.
StreamingLLM은 처음과 최근 토큰만 유지하는 방식인데, 중간에 있는 중요한 정보를 잃을 수 있다는 약점이 있어요. MSA는 위치가 아닌 어텐션 스코어 기반으로 중요 토큰을 판단하기 때문에 더 유연하죠.
이런 기법들이 계속 나오는 건, 결국 LLM의 실용적 배포에서 메모리가 가장 큰 병목이기 때문이에요. GPU 하나에 올릴 수 있는 모델 크기와 처리할 수 있는 컨텍스트 길이가 직접적으로 서비스 비용과 연결되거든요.
한국 개발자에게 주는 시사점
LLM을 서비스에 직접 올려서 운영하고 있거나, 파인튜닝을 하고 있는 팀이라면 MSA 같은 메모리 최적화 기법에 관심을 가져볼 만해요. 특히 한국의 많은 스타트업들이 제한된 GPU 리소스로 LLM 서비스를 운영하고 있는데, KV 캐시 최적화만 잘 해도 같은 GPU로 더 긴 컨텍스트를 처리하거나, 동시에 더 많은 요청을 받을 수 있거든요.
GitHub에 오픈소스로 공개되어 있으니 코드를 직접 살펴보면서 어텐션 메커니즘의 내부 동작을 이해하는 데도 좋은 학습 자료가 될 거예요. 트랜스포머 아키텍처를 공부하고 있는 분이라면 "왜 어텐션이 비싼지, 어떻게 효율화할 수 있는지"를 실제 코드로 확인할 수 있는 기회예요.
정리
MSA는 LLM 어텐션의 메모리 병목을 중요도 기반 스파스 전략으로 해결하려는 실용적 접근이에요. 여러분은 LLM 서비스를 운영하면서 메모리나 비용 문제를 어떻게 해결하고 계신가요? 어텐션 최적화 외에 다른 전략이 있다면 공유해주세요.
🔗 출처: Hacker News
"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공