파일 찾기, 아직도 이름으로 하고 계세요?
컴퓨터를 오래 쓰다 보면 "그 파일 어디 갔지?"라는 상황을 자주 겪게 되는데요. 파일 이름이 기억 안 나고, 어느 폴더에 넣었는지도 모르겠고, 기억나는 거라곤 "노을 사진이었는데…" 같은 모호한 기억뿐일 때가 있잖아요. 이럴 때 파일 이름이 아니라 내용이나 의미로 검색할 수 있다면 얼마나 좋을까요?
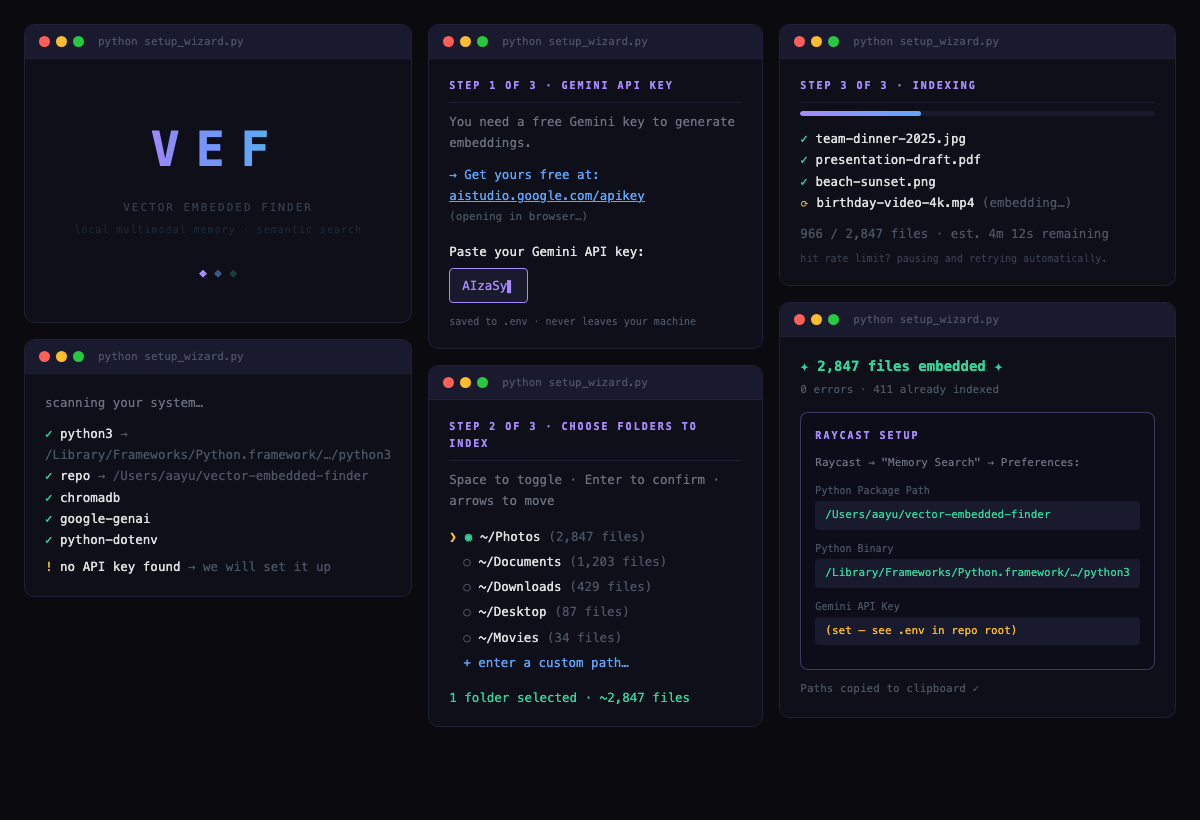
바로 그 문제를 풀려는 오픈소스 프로젝트가 나왔어요. 이름은 Recall이고, 로컬 환경에서 돌아가는 멀티모달 시맨틱 검색 도구예요.
시맨틱 검색이 뭔데요?
보통 우리가 파일을 찾을 때는 키워드 검색을 쓰잖아요. 파일 이름에 "보고서"가 들어있으면 "보고서"로 검색하는 식이죠. 근데 시맨틱 검색은 좀 달라요. "의미(semantic)"를 기반으로 검색하는 거거든요.
이게 뭐냐면, AI가 파일의 내용을 읽고 그 의미를 숫자 벡터(임베딩이라고 불러요)로 변환해놓는 거예요. 나중에 "바다 풍경 사진"이라고 검색하면, 파일 이름이 IMG_20250315.jpg여도 그 사진 속에 바다가 있다면 찾아주는 거죠. 텍스트 문서도 마찬가지예요. "머신러닝 성능 최적화 방법"이라고 검색하면, 제목에 그 단어가 없더라도 내용이 관련된 문서를 찾아줘요.
멀티모달이라는 건 텍스트만이 아니라 이미지, PDF 등 여러 종류(모달)의 파일을 다 처리할 수 있다는 뜻이에요.
Recall은 어떻게 동작하나요?
Recall의 핵심 구조는 크게 세 단계로 나뉘어요.
첫 번째는 인덱싱 단계예요. 지정한 폴더 안의 파일들을 쭉 돌면서, 각 파일의 내용을 AI 모델로 분석해요. 텍스트 파일은 텍스트 임베딩 모델이, 이미지는 비전 모델이 처리하죠. 이렇게 만든 벡터들을 로컬 벡터 데이터베이스에 저장해요.
두 번째는 검색 단계인데요. 사용자가 자연어로 질문을 던지면, 그 질문도 똑같이 벡터로 변환한 뒤 저장된 벡터들과 유사도를 비교해요. 코사인 유사도라는 수학적 방법을 쓰는데, 쉽게 말하면 "두 벡터가 얼마나 같은 방향을 가리키느냐"를 보는 거예요. 방향이 비슷할수록 의미가 비슷한 거죠.
세 번째는 결과 반환이에요. 유사도가 높은 순서대로 파일 목록을 보여주는 거예요.
중요한 건 이 모든 과정이 로컬에서 돌아간다는 점이에요. 클라우드에 파일을 올릴 필요가 없으니 프라이버시 걱정이 없어요. 회사 기밀 문서나 개인 사진 같은 민감한 파일도 안심하고 인덱싱할 수 있죠.
비슷한 도구들과 뭐가 다를까?
사실 비슷한 시도를 한 프로젝트가 꽤 있어요. macOS의 Spotlight나 Windows Search 같은 기본 검색도 있고, 좀 더 고급으로는 Apple의 Finder에 AI 검색이 점점 들어오고 있죠. 그리고 Rewind.ai(지금은 Limitless로 이름 바꿨죠)처럼 화면을 계속 녹화해서 검색하는 극단적인 접근도 있었고요.
그런데 Recall이 차별화되는 지점은 완전 오픈소스이면서 로컬 전용이라는 거예요. Rewind 같은 서비스는 편리하지만 데이터가 외부로 나갈 수 있다는 우려가 있었잖아요. 그리고 OS 기본 검색은 시맨틱 검색까지는 지원하지 않는 경우가 대부분이에요. Recall은 이 두 가지 문제를 동시에 해결하려는 포지션인 거죠.
물론 아직 초기 프로젝트라서 한계도 분명해요. 인덱싱 속도나 지원 파일 형식의 범위, 그리고 검색 정확도 같은 부분은 성숙한 상용 제품과 비교하면 갈 길이 있을 거예요.
한국 개발자에게 어떤 의미가 있을까?
당장 실무에서 쓸 수 있는 수준인지는 직접 테스트해봐야 알겠지만, 몇 가지 쓸모 있는 시나리오가 떠올라요.
하나는 사내 문서 검색이에요. 회사에서 쌓이는 기술 문서, 회의록, 디자인 파일 등이 슬랙이나 노션에 흩어져 있는 경우가 많잖아요. 이런 걸 로컬에 동기화해놓고 시맨틱 검색을 걸면, "지난번에 결제 모듈 리팩토링 논의한 문서" 같은 식으로 찾을 수 있을 거예요.
또 하나는 개인 지식 관리에요. 개발하면서 모아둔 블로그 글, 튜토리얼, 스크린샷 같은 걸 한 폴더에 모아놓고 검색하는 식이죠. 옵시디언이나 노션 같은 노트 앱과 조합하면 꽤 강력한 개인 지식 베이스가 될 수도 있어요.
무엇보다 벡터 검색, 임베딩, RAG(Retrieval-Augmented Generation) 같은 개념이 요즘 AI 애플리케이션의 핵심 패턴으로 자리 잡고 있는데, Recall 같은 프로젝트의 코드를 읽어보는 것 자체가 좋은 학습이 될 수 있어요. 실제로 로컬 벡터 DB를 어떻게 쓰는지, 멀티모달 임베딩을 어떻게 처리하는지 코드 레벨에서 배울 수 있거든요.
정리하자면
파일 검색의 미래는 이름이 아니라 "의미"로 찾는 방향으로 가고 있고, Recall은 그걸 오픈소스와 로컬 환경이라는 조건 위에서 시도하는 프로젝트예요.
여러분은 파일 찾을 때 가장 불편한 점이 뭐예요? 로컬 AI 검색이 그 문제를 풀어줄 수 있을까요?
🔗 출처: Hacker News
"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공