세계 최대 규모의 유전체 데이터, 왜 공공 코드 저장소에 있을까
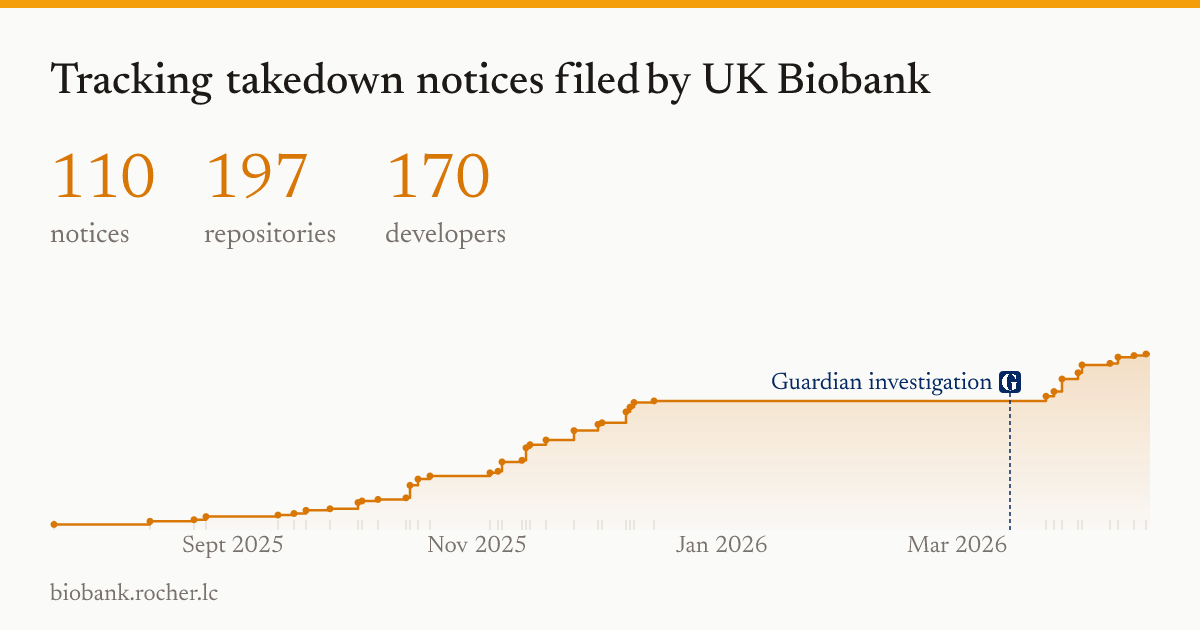
UK Biobank를 아시나요? 영국 정부와 여러 연구 기관이 운영하는 세계 최대 수준의 의료·유전체 데이터베이스예요. 50만 명 규모의 자원자로부터 DNA, 혈액, MRI, 설문 데이터까지 수십 년치를 모아둔 연구 자산이에요. 당연히 접근은 엄격하게 통제되어 있고, 연구자가 정식 신청·심사를 거쳐야 일부 데이터에 접근할 수 있어요. 그런데 이 데이터의 조각들이 지금도 계속해서 GitHub에 올라오고 있다는 문제가 제기됐어요.
이걸 추적해 보여주는 biobank.rocher.lc 사이트는 공개 레포에서 발견되는 UK Biobank 유래 데이터 파일들을 모아서 드러내고 있어요. 연구자들이 논문 재현용 코드를 공개하면서, 또는 분석 스크립트를 버전 관리하면서 실수로 원본/파생 데이터까지 함께 푸시한 경우가 상당수예요. 한두 건이 아니라 반복적으로, 여러 기관에서 발생한다는 게 핵심이에요.
왜 이런 일이 계속 생길까
가장 큰 원인은 연구 워크플로우와 소프트웨어 엔지니어링 워크플로우의 간극이에요. 연구실에선 보통 한 명의 박사과정생이나 포닥이 데이터를 내려받아 로컬에서 분석하고, 그 결과를 논문으로 정리하는 방식으로 일해요. 이 과정에서 Jupyter 노트북이나 R 스크립트가 자라나고, 그걸 그대로 GitHub에 올리는 게 "재현 가능한 연구"의 모범답안으로 여겨지거든요. 문제는 노트북 안에 중간 결과로 유전자 변이 테이블이나 개인별 표현형 벡터가 그대로 박혀 있다는 거예요. .ipynb 파일은 텍스트지만 그 안에 출력 셀로 데이터가 저장되기 때문에, 무심코 커밋하면 그대로 새어나가요.
또 하나는 파생 데이터에 대한 감수성 부족이에요. 연구자들은 종종 "원본 유전체 파일만 아니면 괜찮다"고 생각하는데, 실제로는 특정 SNP(유전자 변이)와 표현형 조합만으로도 개인 식별이 가능하다는 논문이 여러 편 나와 있어요. 즉 익명화된 것처럼 보이는 파생 테이블도 재식별 리스크가 있다는 거죠. UK Biobank 이용 약관도 이 부분을 금지하지만, 실제 연구 현장에서는 이 경계가 흐릿하게 지켜지는 경우가 많아요.
기술적으로 어떻게 막을 수 있을까
방법은 여러 가지예요. 가장 간단한 건 .gitignore와 프리커밋 훅을 잘 세팅하는 거예요. .bgen, .vcf, *.pheno 같은 확장자를 기본 차단하고, 노트북은 커밋 전에 nbstripout으로 출력 셀을 제거하는 식이에요. 조금 더 본격적인 팀이라면 git-secrets나 gitleaks 같은 도구로 민감 패턴을 스캔하거나, 아예 TRE(Trusted Research Environment, 믿을 수 있는 연구 환경 — 데이터가 서버 밖으로 나가지 못하게 격리된 분석 공간) 안에서만 분석하게 강제할 수 있어요. 실제로 UK Biobank도 최근 몇 년간 TRE 방향으로 정책을 전환하고 있고, DNAnexus 기반의 Research Analysis Platform이 그 결과물이에요.
그럼에도 새어나가는 건 결국 사용자가 직접 파일을 다운로드해서 로컬에서 돌린 뒤 그 결과물을 공개 저장소에 올리는 경로가 살아 있기 때문이에요. 이걸 막으려면 정책뿐 아니라 툴체인 자체를 바꿔야 해요.
업계 맥락
비슷한 이슈는 다른 영역에서도 반복돼요. 기업 코드베이스에서 AWS 키가 새는 문제, 의료 기관 코드에서 환자 식별자가 새는 문제, 그리고 최근엔 LLM 학습 데이터에 개인정보가 포함되는 문제까지 결이 같아요. 공통점은 "개발자가 일하기 편한 경로"와 "데이터 보호 정책"이 충돌하는 지점에서 사고가 난다는 거예요.
유럽에서는 GDPR 때문에 재식별 가능 데이터 유출이 곧장 제재로 이어져요. UK Biobank 유출은 단순 실수로 끝날 일이 아니라, 해당 연구자와 소속 기관의 데이터 접근 권한 자체가 회수될 수 있는 사안이에요.
한국 개발자에게
의료 AI나 바이오 쪽 일을 하는 분이라면 남 얘기가 아니에요. 국내에서도 건강보험공단, K-CURE, 질병관리청 데이터 등 민감 데이터가 점점 많이 공개되고 있고, 이걸 다루는 팀의 보안 수준은 편차가 커요. 사내 Git 환경에 프리커밋 훅이 있는지, 노트북 출력 셀이 그대로 커밋되는 문화인지 한 번쯤 점검해볼 가치가 있어요. 특히 병원 협업 프로젝트에서는 한 번의 실수가 기관 전체의 공동연구 자격을 위태롭게 할 수 있거든요.
마무리
"실수로 푸시했어요"가 더 이상 변명이 되지 않는 시대예요. 여러분의 레포에는 지금 이 순간 새어나가면 안 될 무엇이 들어가 있진 않나요?
🔗 출처: Hacker News

"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공