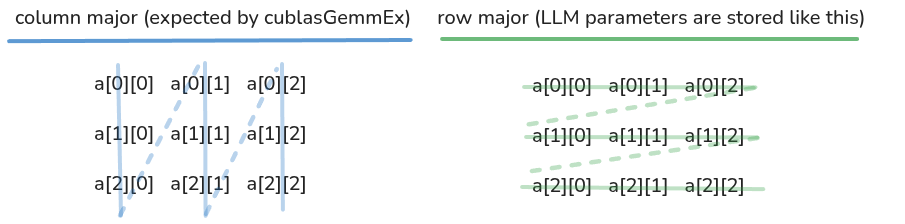
vLLM의 미니어처 버전이 등장했어요
LLM을 직접 서빙해본 분들이라면 vLLM이라는 이름을 한번쯤 들어보셨을 거예요. UC Berkeley에서 시작된 오픈소스 프로젝트인데, GPU 메모리를 효율적으로 관리해서 LLM을 빠르게 돌릴 수 있게 해주는 추론 엔진이에요. 지금은 거의 표준이 되어서 OpenAI 호환 API 서버를 띄울 때 가장 많이 쓰이고 있죠.
그런데 최근 Tiny-vLLM 이라는 프로젝트가 공개됐어요. 이름 그대로 "vLLM의 본질만 뽑아서 직접 C++와 CUDA로 다시 짠 작은 버전"이에요. 만든 사람은 jmaczan라는 개발자인데, "vLLM이 어떻게 동작하는지 깊이 이해하고 싶어서 처음부터 직접 만들어봤다"고 해요. 일종의 학습용 프로젝트지만, 실제로 추론을 돌릴 수 있는 수준이라는 점에서 흥미로워요.
vLLM의 핵심을 짧게 짚으면
Tiny-vLLM이 뭘 다시 구현한 건지 이해하려면 vLLM의 핵심 아이디어를 알아야 해요. 가장 중요한 건 PagedAttention 이라는 메커니즘이에요. 이게 뭐냐면, LLM이 토큰을 하나씩 생성할 때마다 이전 토큰들의 "기억"인 KV 캐시(Key-Value cache)를 GPU 메모리에 저장해두거든요. 이 캐시가 어마어마하게 커요. 문제는 일반적인 방식으로 메모리를 잡으면, 메모리 단편화 때문에 절반 가까이가 낭비된다는 거예요.
vLLM은 운영체제의 가상 메모리 페이징처럼 KV 캐시를 작은 블록 단위로 쪼개서 관리해요. 덕분에 메모리 활용률이 90% 이상으로 올라가고, 같은 GPU에서 더 많은 요청을 동시에 처리할 수 있어요. 처리량이 보통 2~4배 빨라지죠.
또 하나는 continuous batching 이에요. 보통 배치 처리는 "요청 N개가 모두 끝날 때까지 기다렸다가 다음 배치"인데, vLLM은 한 요청이 끝나면 바로 새 요청을 끼워 넣어요. GPU가 놀지 않도록 계속 일을 시키는 거죠.
Tiny-vLLM은 뭐가 다른가
Tiny-vLLM은 이런 핵심 메커니즘을 순수 C++와 CUDA 커널로 직접 구현했어요. 원본 vLLM은 Python 위에서 PyTorch와 CUDA를 섞어 쓰는데, Tiny-vLLM은 PyTorch 의존성을 빼고 CUDA 커널을 직접 짜요. 그래서 코드 베이스가 훨씬 작고, 추론 엔진이 내부적으로 어떻게 굴러가는지 코드를 따라가며 학습하기 좋아요.
주요 구성 요소는 이래요. 트랜스포머 모델의 forward pass를 직접 구현하고, PagedAttention 스타일의 KV 캐시 매니저를 만들고, 간단한 스케줄러로 요청들을 GPU에 어떻게 분배할지 결정해요. 토큰화도 자체 처리하고요. 물론 vLLM의 모든 최적화(예: speculative decoding, prefix caching, 다양한 양자화)를 다 구현한 건 아니지만, 핵심 흐름은 잡혀 있어요.
성능은 본가 vLLM에 비하면 당연히 떨어지지만, 단일 GPU에서 작은 모델(예: Llama 1B~7B 정도)을 돌리기에는 충분한 수준이라고 해요. 무엇보다 "vLLM이 어떻게 그렇게 빠른지" 를 코드로 이해할 수 있다는 게 핵심 가치예요.
업계 맥락
LLM 추론 엔진 시장은 의외로 경쟁이 치열해요. vLLM 외에도 NVIDIA의 TensorRT-LLM, HuggingFace의 TGI(Text Generation Inference), SGLang, MLC-LLM 같은 프로젝트들이 각자의 방식으로 추론 속도를 올리고 있죠. 최근에는 "LLM 추론의 시스템 프로그래밍"이 다시 핫한 분야가 됐어요. GPU 성능을 마지막 10%까지 짜내는 건 모델 정확도를 1% 올리는 것보다 ROI가 훨씬 높거든요.
Tiny-vLLM 같은 미니 구현체의 흐름도 함께 늘고 있어요. Karpathy의 llama.c, nanoGPT, llama2.c, llm.c 같은 "처음부터 다시 만들어보는" 시리즈가 인기를 끌었잖아요. Tiny-vLLM도 그 연장선상에 있어요. "이해하려면 직접 만들어봐야 한다" 는 옛 격언이 LLM 시대에도 통한다는 증거죠.
한국 개발자에게 주는 시사점
LLM 인프라 쪽에서 일하는 분들에게 이런 작은 구현체는 진짜 보물이에요. vLLM 본가 코드는 너무 방대해서 처음 보면 어디부터 봐야 할지 막막한데, Tiny-vLLM은 코드가 작아서 며칠이면 전체를 훑을 수 있거든요. "PagedAttention이 실제로 어떻게 메모리를 관리하지?" 같은 질문에 코드 레벨로 답을 찾을 수 있어요.
실무에서는 Tiny-vLLM을 그대로 쓰진 않겠지만, CUDA 커널 작성, GPU 메모리 관리, 추론 스케줄링 같은 스킬을 익히는 데 좋은 교재예요. 요즘 한국 회사들도 자체 LLM 추론 인프라를 구축하려는 시도가 늘고 있는데, 시스템 레벨 LLM 엔지니어 수요가 빠르게 커지고 있어요. 이 분야는 ML 지식과 시스템 프로그래밍 지식을 둘 다 요구해서 진입장벽이 높지만, 그만큼 희소성도 커요.
마무리
Tiny-vLLM은 "가벼움"이 무기가 아니라 "이해 가능함"이 무기인 프로젝트예요. LLM 인프라의 블랙박스를 한 꺼풀 벗겨주는 좋은 학습 자료죠.
여러분은 LLM 추론 엔진을 직접 만들어보고 싶다는 생각을 해보신 적 있나요? 아니면 vLLM 같은 기존 솔루션을 그냥 잘 쓰는 게 더 실용적이라고 보세요?
🔗 출처: Hacker News
"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공