"GPU 사용률 99%"라는 함정
LLM 학습이나 추론을 돌려보신 분들은 한 번쯤 nvidia-smi 명령어를 쳐보셨을 거예요. 거기서 GPU-Util이 99%, 100% 찍히는 걸 보면 "오, GPU 빡세게 일하고 있구나" 싶은데요. 사실 이 숫자가 의외로 거짓말쟁이라는 거, 알고 계셨나요? 이 값은 단지 "지난 1초 동안 GPU의 SM(Streaming Multiprocessor, GPU 안의 작은 연산 코어 묶음) 중 단 하나라도 일하고 있던 시간의 비율"이거든요. 즉, GPU 안에 수천 개 연산기가 있는데 그중 1개만 돌아가도 100%로 표시될 수 있다는 뜻이에요. 이게 뭐가 문제냐면, 실제로는 80%가 놀고 있는데도 모니터링 대시보드에서는 "꽉 차 있음"으로 보여서 비싼 GPU 자원이 줄줄 새고 있는데도 모를 수 있다는 거예요.
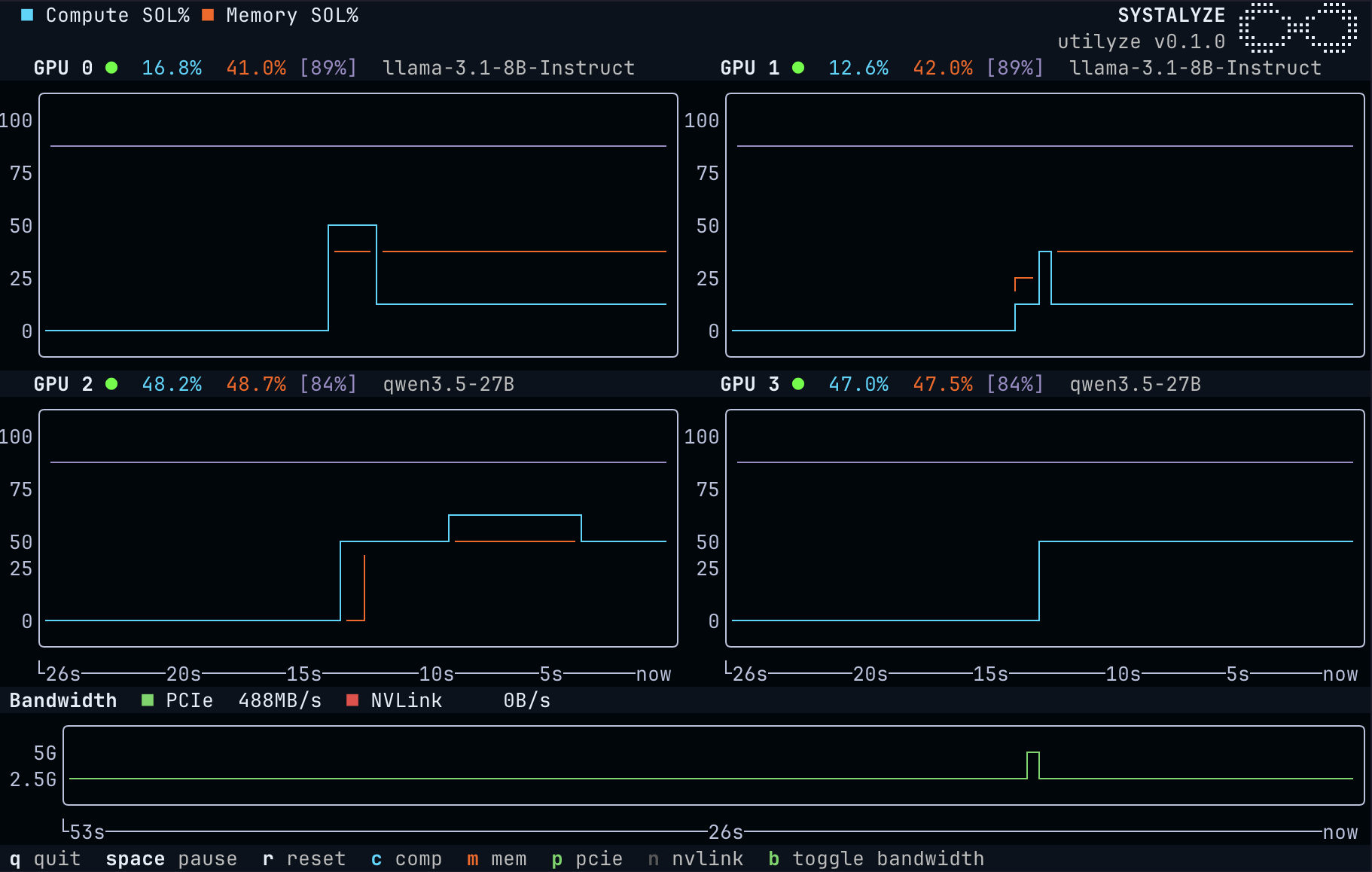
바로 이 지점에서 등장한 게 Utilyze라는 오픈소스 도구예요. systalyze라는 팀이 GitHub에 공개했고, 이름 그대로 "GPU가 진짜 유용한 일을 얼마나 효율적으로 하고 있는지"를 측정하는 데 초점이 맞춰져 있어요.
무엇을 어떻게 측정하는가
Utilyze가 보는 지표는 단순한 사용률이 아니에요. 핵심은 MFU(Model FLOPs Utilization)와 HFU(Hardware FLOPs Utilization) 같은 "진짜 일한 양" 기반 지표예요. 이게 뭐냐면, GPU 스펙시트에 적힌 이론적 최대 연산량(예를 들어 H100의 경우 BF16 기준 약 989 TFLOPS) 대비 내가 실제로 모델 학습/추론하면서 뽑아내고 있는 연산량이 몇 퍼센트인가를 보는 거예요. 이 수치가 30%면 GPU가 100% 사용 중인 것처럼 보여도 실은 70%의 잠재력을 못 끌어쓰고 있는 거죠.
Utilyze는 여기에 더해서 메모리 대역폭 사용률, 텐서 코어 활용률, SM 점유율(occupancy) 같은 저수준 지표도 같이 잡아줘요. 이 지표들을 한 번에 보면 "내 워크로드가 메모리 바운드인지(데이터 못 가져와서 노는 건지), 컴퓨트 바운드인지(연산이 빡빡한 건지)"를 진단할 수 있어요. 보통 LLM 추론은 메모리 대역폭에 묶여서 텐서 코어가 놀고, 학습은 컴퓨트 바운드에 가까운 패턴을 보이거든요. 이걸 알아야 "배치 사이즈를 늘릴까, KV 캐시 양자화를 할까, 플래시 어텐션을 적용할까" 같은 최적화 방향이 정해져요.
비슷한 도구들과 비교하면
GPU 프로파일링 시장에는 이미 강자들이 있어요. 엔비디아 공식 도구인 Nsight Systems나 Nsight Compute는 거의 현미경 수준으로 커널 하나하나를 까볼 수 있고요. PyTorch Profiler는 프레임워크에 박혀 있어서 학습 코드에 바로 붙이기 좋아요. DCGM(Data Center GPU Manager)는 데이터센터 단위로 모니터링할 때 쓰이고요.
Utilyze의 포지션은 이 사이의 빈틈이에요. Nsight는 너무 무겁고 깊어서 일상 모니터링용으로 쓰기 부담스럽고, nvidia-smi는 너무 얕고 부정확하거든요. Utilyze는 "가볍게 띄워놓고 진짜 효율을 실시간으로 보고 싶다"는 수요를 노린 거예요. CLI 한 줄로 띄울 수 있고, 의존성도 무겁지 않다는 게 강점이고요.
한국 개발자에게 주는 시사점
요즘 한국에서도 자체 LLM을 학습하거나, 사내에 GPU 서버를 운영하는 회사들이 많아졌잖아요. H100 한 대가 한 시간에 몇천 원씩 나가는 클라우드 환경에서 MFU가 20%인지 50%인지는 비용을 두 배 이상 가르는 차이예요. 같은 모델을 같은 시간에 돌려도 효율이 두 배 좋으면 돈이 절반만 나가는 거니까요.
특히 추론 서빙을 직접 운영하는 팀이라면 Utilyze 같은 도구로 측정해보면 깜짝 놀랄 거예요. 많은 경우에 GPU "사용률"은 90% 넘는데 MFU는 10~20%대인 상황이 흔하거든요. 이건 vLLM이나 TGI 같은 서빙 프레임워크 튜닝, 양자화 적용, 배치 전략 변경 같은 액션 아이템으로 바로 이어져요.
반대로 말하면, 자기 워크로드의 특성을 모르고 무작정 GPU를 더 사면 돈만 태우는 거예요. "우리 서비스는 메모리 바운드라서 GPU를 늘리는 것보다 양자화가 답이다" 같은 결론을 데이터로 내릴 수 있어야 엔지니어링 결정이 단단해져요.
정리
핵심은 이거예요. GPU 사용률은 거짓말을 한다. 진짜 봐야 할 건 "이론 최대 대비 얼마나 뽑아내고 있느냐"다. Utilyze는 그걸 가볍게 보여주는 도구고요. 여러분 팀에서는 GPU 효율을 어떻게 모니터링하고 계신가요? nvidia-smi만 보고 있다면, 한 번쯤은 MFU를 직접 계산해볼 만한 시점이에요.
🔗 출처: Hacker News

"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공