SSD 시대에 웬 하드디스크 이야기?
노트북도 서버도 대부분 SSD로 넘어간 지금, 회전하는 원판이 들어있는 하드디스크(HDD) 이야기를 한다는 게 좀 의외일 수 있어요. 그런데 이 글은 단순한 옛날 이야기가 아닙니다. "하드디스크의 내부 구조를, 그 구조를 모르는 상태에서 측정만으로 알아내는" 일종의 탐정 놀이 같은 글이거든요. 디스크 회사가 공개하지 않는 정보를 마이크로벤치마크로 역추적해내는 과정이 흥미로워서, 시스템 프로그래밍이나 성능 분석에 관심 있으신 분들이라면 분명 재밌게 읽으실 만해요. 게다가 여기서 쓰는 기법들은 SSD, 메모리 계층, 캐시 분석 같은 현대 시스템에도 그대로 응용됩니다.
하드디스크 구조 잠깐 복습
하드디스크는 회전하는 원판(platter) 여러 장이 쌓여 있고, 각 면에 헤드(head)가 떠다니면서 데이터를 읽고 써요. 데이터는 동심원 모양의 트랙(track)에 저장되고, 트랙은 다시 작은 섹터(sector)로 나뉩니다. 옛날엔 사용자가 실린더-헤드-섹터(CHS) 주소를 직접 다뤘는데, 요즘 하드디스크는 그냥 0번부터 시작하는 일렬의 번호(LBA, Logical Block Address)만 외부에 노출해요. 내부에서 LBA를 어떤 트랙·섹터로 매핑하는지는 제조사 비밀입니다.
그런데 성능 분석이나 데이터 복구, 포렌식 작업을 하다 보면 이 매핑을 알고 싶을 때가 생겨요. 예를 들어 "이 두 LBA가 같은 트랙에 있는가?", "바깥쪽 트랙은 안쪽보다 섹터가 몇 개 더 많은가?" 같은 질문이요. 이런 걸 알면 데이터 배치를 최적화하거나 디스크 수명을 예측할 수 있거든요.
어떻게 알아내냐면요
핵심 아이디어가 정말 우아해요. "읽기 시간만 측정해서 물리 구조를 추론한다"는 거예요. 어떻게 가능할까요?
하드디스크에서 데이터를 읽는 데 걸리는 시간은 크게 두 부분으로 나뉘어요. 첫째, 헤드를 원하는 트랙으로 이동시키는 탐색 시간(seek time). 둘째, 그 트랙에서 원하는 섹터가 헤드 아래로 돌아올 때까지 기다리는 회전 지연(rotational latency). 같은 트랙 안의 두 섹터를 연속으로 읽으면 탐색 시간이 0이고 회전 지연만 있어요. 다른 트랙이면 탐색 시간이 추가되죠.
그래서 두 개의 LBA를 골라 번갈아 읽어보면, 평균 읽기 시간으로 "이 둘이 같은 트랙인가, 인접 트랙인가, 멀리 떨어진 트랙인가"를 추정할 수 있어요. 더 정교하게는 회전 주기를 측정해서, 한 트랙에 섹터가 몇 개 들어있는지까지 계산할 수 있습니다. 마치 우물에 돌을 떨어뜨리고 소리가 돌아오는 시간으로 깊이를 재는 것처럼, 시간만 가지고 보이지 않는 구조를 그려내는 거예요.
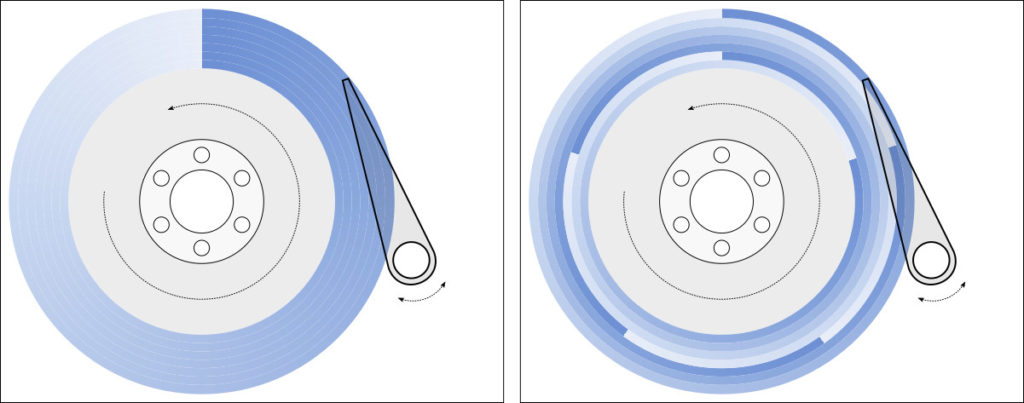
존(Zone) 구조의 발견
글쓴이는 이 기법으로 흥미로운 사실을 확인합니다. 현대 하드디스크는 존 비트 레코딩(ZBR, Zoned Bit Recording)이라는 방식을 써요. 바깥쪽 트랙은 둘레가 길어서 더 많은 섹터를 담을 수 있고, 안쪽으로 갈수록 섹터가 줄어들어요. 그래서 디스크는 여러 개의 "존"으로 나뉘고, 각 존마다 트랙당 섹터 수가 달라집니다.
이걸 측정으로 확인하면 "바깥쪽 LBA는 안쪽 LBA보다 순차 읽기 속도가 빠르다"는 결과가 나와요. 같은 시간 동안 헤드 아래를 더 많은 섹터가 지나가니까요. 실제로 바깥쪽이 안쪽보다 거의 2배 빠른 디스크도 흔합니다. 그래서 옛날 시스템 관리자들은 자주 쓰는 데이터를 디스크 앞부분(바깥쪽 트랙에 매핑되는 LBA)에 배치하는 "숏 스트로킹(short stroking)" 기법을 쓰기도 했어요.
왜 이런 게 재밌을까
이 글이 흥미로운 건, 하드디스크 자체보다 "블랙박스를 측정으로 분석하는 사고법" 때문이에요. 같은 접근이 현대 시스템 곳곳에 적용됩니다.
예를 들어 CPU 캐시 라인 크기와 L1/L2/L3 캐시 용량도 메모리 접근 시간 패턴을 측정해서 알아낼 수 있어요. Ulrich Drepper의 유명한 글 "What Every Programmer Should Know About Memory"가 바로 이런 기법으로 가득 차 있죠. SSD의 내부 매핑(FTL)도 비슷한 방법으로 추론할 수 있고요. GPU의 워프 스케줄링이나 메모리 뱅크 충돌도 마이크로벤치마크로 드러납니다. 더 나아가 클라우드 가상 머신이 같은 물리 서버에 있는지 확인하는 보안 연구도 비슷한 사이드 채널 기법을 써요.
한국 개발자에게는
당장 하드디스크의 트랙 구조를 알아낼 일은 없을 거예요. 하지만 이 글이 보여주는 사고방식은 실무에서 굉장히 유용합니다.
첫째, 성능 문제를 만나면 "측정"으로 시작하는 습관이에요. 추측이나 직관 대신, 작은 벤치마크를 짜서 실제 동작을 확인하는 거죠. 예를 들어 데이터베이스 쿼리가 느릴 때 "인덱스가 없겠지"라고 추측하지 말고, EXPLAIN으로 실제 실행 계획을 보고, 시간을 측정해서 어디가 병목인지 찾아내는 식이에요.
둘째, 블랙박스를 그대로 받아들이지 않는 자세예요. 클라우드 데이터베이스든, 외부 API든, 사용 중인 라이브러리든, 문서가 말하지 않는 동작을 측정으로 확인할 수 있어요. "이 API 호출이 정말 캐시되는가?", "이 ORM이 N+1 쿼리를 만드는가?" 같은 질문에 답하는 가장 확실한 방법은 직접 측정하는 겁니다.
셋째, 시스템 프로그래밍 기초의 깊이예요. 회전 지연이나 탐색 시간 같은 개념은 옛날 이야기 같지만, 메모리 접근 비용, 네트워크 RTT, 디스크 IOPS 같은 현대적인 성능 지표의 사고 틀은 똑같아요. "왜 느린가"를 물리적 원인까지 추적하는 훈련은 어느 시대에도 가치가 있습니다.
정리하자면
하드디스크 같은 블랙박스의 내부 구조를, 시간 측정만으로 우아하게 역추적해내는 사례입니다. 이 사고법은 캐시, SSD, 클라우드 인프라까지 현대 시스템 분석에 두루 활용할 수 있는 강력한 도구예요.
여러분은 최근 어떤 시스템의 "숨겨진 동작"을 측정으로 알아낸 경험이 있으신가요? 추측이 아니라 측정으로 답을 찾았던 디버깅 사례가 있다면 공유해 주세요.
🔗 출처: Hacker News


"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공