거대 모델을 어디서 돌릴 것인가
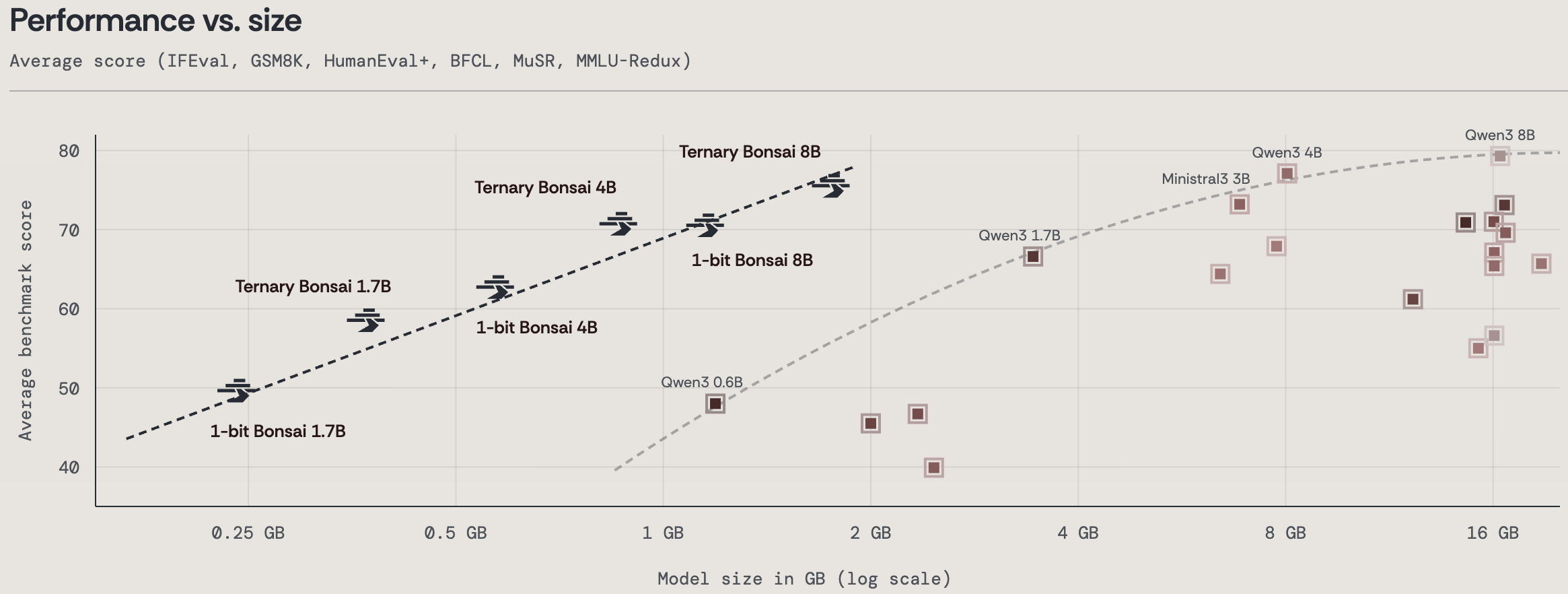
AI 모델이 점점 커지면서 한 가지 고민이 커지고 있어요. 700억, 4,000억, 1조 파라미터를 가진 모델들을 도대체 어디에 어떻게 돌릴 거냐는 거죠. GPT-4급 모델을 원본 그대로 돌리려면 A100이나 H100 GPU를 수십 장씩 묶어야 하는데, 이게 돈이 어마어마하게 들어요. 그래서 "모델을 압축해서 같은 성능을 내면서 메모리와 전력은 덜 먹게 하자"는 양자화(quantization) 연구가 활발해졌어요. PrismML이라는 연구팀이 최근 공개한 Ternary Bonsai(삼진수 본사이)는 이 방향의 극단을 보여주는 프로젝트예요. 이름 그대로 모델 파라미터를 단 세 개의 값(-1, 0, 1)만 써서 표현하는, 이른바 1.58비트 모델이에요.
비트를 줄인다는 게 무슨 뜻일까
처음 접하시는 분들을 위해 설명하면 이래요. 일반적인 신경망 모델은 가중치 하나를 FP16(16비트 부동소수점)이나 FP32(32비트)로 저장해요. 숫자 하나가 16비트면 0.1234567 같은 정밀한 소수를 표현할 수 있죠. 근데 이걸 INT8(8비트 정수)로 줄이면 용량이 절반, INT4로 줄이면 4분의 1이 돼요. 여기서 더 공격적으로 가서, 가중치를 딱 세 가지 값(-1, 0, 1)만으로 표현하면 어떻게 될까요? 그게 ternary(3진수) 양자화예요. 세 개의 값을 저장하려면 수학적으로 log₂(3) ≈ 1.58비트가 필요해서 "1.58비트 모델"이라고 불러요.
이 아이디어 자체는 마이크로소프트 리서치가 2024년에 발표한 BitNet b1.58에서 먼저 제시했어요. 그때 충격적이었던 건, 이 극단적인 압축에도 불구하고 3B 이상 규모에서 FP16 모델과 거의 비슷한 성능을 냈다는 거예요. Ternary Bonsai는 이 계보를 이어서, 더 큰 스케일에서도 성능 저하 없이 돌릴 수 있는 학습 레시피와 추론 엔진을 만든 셈이에요.
왜 이게 혁신적일까
성능이 비슷하다고 해도, 왜 굳이 1.58비트로 줄이는 게 중요할까요? 이점이 세 가지 있어요.
첫째는 메모리예요. 70B 모델을 FP16으로 저장하면 140GB가 필요해서 H100 두 장이 있어야 돼요. 같은 모델을 1.58비트로 압축하면 14GB도 안 되기 때문에, 노트북 GPU나 M 시리즈 맥에서도 돌릴 수 있어요. 엣지 디바이스에 거대 모델을 올리는 게 현실이 되는 거죠.
둘째는 연산 속도예요. 곱셈 연산이 덧셈만으로 바뀌어요. 가중치가 -1, 0, 1밖에 없으니까 입력값에 이걸 곱하는 건 부호를 바꾸거나, 그대로 두거나, 0을 만드는 것뿐이거든요. 곱셈기(multiplier) 회로가 필요 없어서, 이론적으로 전용 칩을 만들면 기존 GPU 대비 10배 이상 빠르고 전력은 몇 분의 1만 먹는 설계가 가능해요.
셋째는 환경과 비용이에요. 거대 AI의 전력 소모가 사회 문제가 되고 있잖아요. 1.58비트 전용 ASIC(특수목적 집적회로)이 상용화되면 AI 서빙 비용을 한 자릿수 %로 떨어뜨릴 수 있다는 예측도 나와요.
다른 압축 기법과는 뭐가 다를까
양자화 쪽에는 여러 경쟁 기법이 있어요. GPTQ, AWQ, SmoothQuant 같은 방식은 기존에 FP16으로 학습된 모델을 나중에 압축해요(Post-Training Quantization). 장점은 재학습이 필요 없다는 거지만, 비트를 4비트 이하로 내리면 성능이 급격히 떨어져요.
반면 BitNet이나 Ternary Bonsai 계열은 처음부터 저비트로 학습해요(QAT, Quantization Aware Training). 학습 과정에서 모델이 저비트 가중치에 맞춰 스스로 적응하니까, 1.58비트라는 극단까지도 내려갈 수 있는 거예요. 다만 처음부터 다시 학습해야 하니까 초기 학습 비용은 크고, 기존에 공개된 Llama나 Qwen 모델을 그대로 가져다 쓸 수는 없다는 단점이 있어요.
한국 개발자에게 주는 시사점
당장 실무에 쓰기엔 아직 이릅니다. 생태계(CUDA 커널, 라이브러리 지원)가 FP16/INT8/INT4에 집중돼 있고, 1.58비트 전용 추론 엔진이나 하드웨어가 널리 보급되지 않았거든요. 하지만 방향은 분명해요. 국내 스타트업 중에 엣지 AI나 온디바이스 LLM을 노리는 곳이라면, 이 흐름을 반드시 주목해야 해요. 스마트폰에 70B 모델을 넣는 게 올해 안에 현실이 될 수도 있거든요.
또 삼성·SK하이닉스가 밀고 있는 PIM(Processing-in-Memory, 메모리 내 연산) 아키텍처와도 궁합이 잘 맞아요. 곱셈이 필요 없는 단순한 덧셈 위주의 연산이 많으니까, 메모리 셀 안에서 바로 계산하는 PIM의 장점이 극대화되거든요. 한국 반도체 업계가 AI 칩 경쟁에서 차별화할 포인트로 삼을 만한 지점이에요.
일단은 허깅페이스에서 BitNet 체크포인트를 받아서 llama.cpp로 한 번 돌려보시는 것부터 시작해보세요. 본인 노트북에서 놀라운 속도를 체감하실 수 있을 거예요.
여러분은 1.58비트 모델이 몇 년 안에 주류가 될 거라고 보시나요? 아니면 결국 FP8/INT4 언저리에서 안정화될 거라고 보시나요?
🔗 출처: Hacker News


"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공