건설 도면이라는 특수한 세계
우리가 흔히 쓰는 OCR(광학 문자 인식)이 있잖아요. 사진 찍으면 텍스트를 뽑아주는 기술이요. 요즘은 GPT-4 같은 멀티모달 AI 덕분에 웬만한 문서는 다 읽어내는 시대가 됐는데요, 건설 도면(construction drawing)만큼은 여전히 골칫거리였어요.
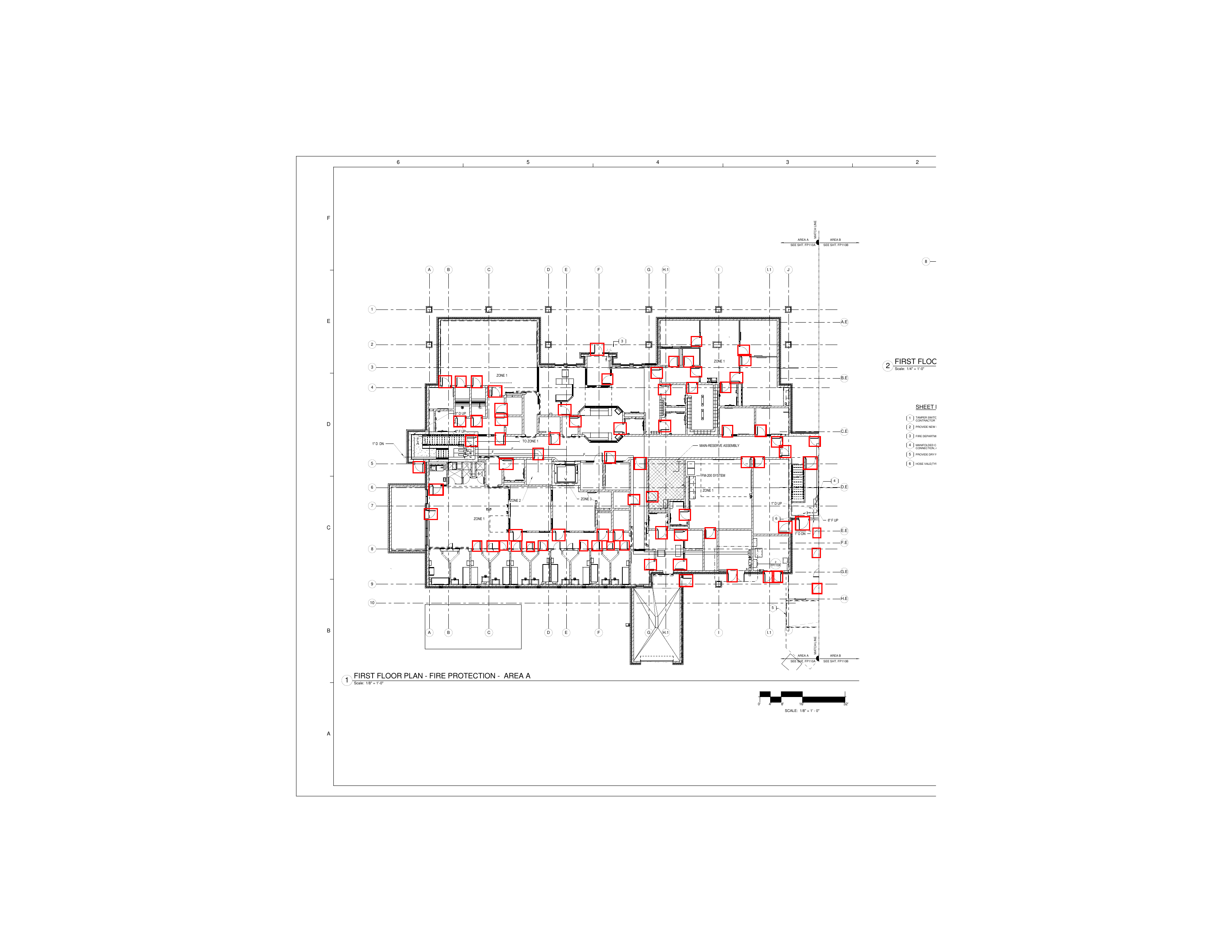
이게 뭐냐면, 건축 현장에서 쓰는 도면은 우리가 보통 생각하는 "문서"와 완전히 다르거든요. A1 사이즈(594×841mm) 이상의 거대한 용지에 수백 개의 문, 창문, 벽체 정보가 빼곡하게 들어가 있어요. 텍스트가 0도, 90도, 심지어 대각선으로 회전돼 있고, 선과 기호가 복잡하게 얽혀 있는데 그 사이사이에 치수(dimension)나 주석(annotation)이 붙어 있죠. 일반 OCR이 이런 도면을 만나면 텍스트를 엉뚱한 위치에 매핑하거나, 회전된 글자를 아예 인식 못 하거나, 테이블 구조를 완전히 무시해 버리는 일이 다반사예요.
AnchorGrid라는 스타트업이 바로 이 문제를 정면으로 파고들었어요. "건설 도면 전용 OCR은 기존 범용 OCR과 근본적으로 다른 접근이 필요하다"는 게 이들의 출발점이에요.
기존 OCR이 건설 도면에서 실패하는 이유
일반적인 OCR 파이프라인을 생각해볼게요. 이미지를 받으면 텍스트 영역을 감지하고, 그 영역 안의 글자를 인식하고, 결과를 반환하는 구조잖아요. Tesseract 같은 전통적인 OCR 엔진이든, 최신 클라우드 API(Google Vision, AWS Textract)든 기본 흐름은 비슷해요.
그런데 건설 도면에서는 이런 문제들이 터져요. 첫째, 스케일 문제예요. 도면 하나가 수천~수만 픽셀짜리 고해상도 이미지인데, 대부분의 OCR 모델은 이 정도 크기를 한 번에 처리하지 못해요. 잘라서(crop) 처리하면 문맥이 끊기고요. 둘째, 구조 인식 문제가 있어요. 도면에는 "도어 스케줄(Door Schedule)"이라는 표가 있는데, 이 표에 문의 규격, 재질, 하드웨어 정보가 빼곡히 담겨 있거든요. 일반 OCR은 이 표의 행과 열 관계를 제대로 파싱하지 못해요. 셋째, 도메인 특화 기호 문제예요. 건설 도면에는 업계만의 약어와 기호가 있는데(예: "HM"은 Hollow Metal, 즉 철제 문틀을 의미), 범용 모델은 이런 맥락을 이해하지 못하죠.
AnchorGrid의 접근 방식
AnchorGrid는 건설 도면에서 특정 정보를 구조화된 데이터로 뽑아내는 API를 만들었어요. 예를 들어 "이 도면 세트에서 모든 문(door) 정보를 추출해줘"라고 요청하면, 각 문의 번호, 크기, 재질, 프레임 타입, 하드웨어 세트 번호까지 JSON으로 깔끔하게 반환해주는 거예요.
이게 가능한 이유는, 범용 OCR처럼 "이미지에서 모든 텍스트를 읽어"가 아니라 "건설 도면이라는 도메인을 이해하고, 도면의 구조(평면도, 스케줄 표, 상세도)를 먼저 파악한 뒤, 각 요소의 관계를 매핑"하는 방식이기 때문이에요. 쉽게 비유하면, 외국어를 단어 하나하나 직역하는 게 아니라, 그 나라의 문화와 맥락을 이해한 상태에서 의역하는 것과 비슷해요.
API 엔드포인트를 보면, 도면 PDF를 업로드하면 도면 내 문(door) 정보를 구조화해서 돌려주는 형태예요. 건설 현장에서는 수백 장의 도면에서 이런 정보를 수작업으로 뽑아내는 데 몇 주씩 걸리는 경우가 많은데, 이걸 API 호출 한 번으로 해결하겠다는 거죠.
업계 맥락: 건설 테크의 AI 도입
건설 산업은 디지털 전환이 가장 느린 분야 중 하나로 알려져 있어요. 맥킨지 보고서에 따르면 건설업의 디지털화 수준은 농업 다음으로 낮다고 하죠. 그만큼 AI가 파고들 틈이 크다는 뜻이기도 해요.
비슷한 영역을 공략하는 서비스로는 Procore, PlanGrid(현재 Autodesk 소속), Bluebeam 같은 건설 관리 소프트웨어가 있는데, 이들은 주로 프로젝트 관리나 도면 뷰어에 초점을 맞추고 있어요. 도면에서 데이터를 자동으로 추출하는 기능은 아직 부족한 편이에요. AnchorGrid는 이 틈새를 AI 기반 문서 이해(document understanding)로 채우려는 시도예요.
더 넓게 보면, 이건 "도메인 특화 AI"라는 큰 트렌드의 일부이기도 해요. 범용 LLM이 아무리 똑똑해져도, 특정 산업의 복잡한 문서를 제대로 처리하려면 해당 도메인의 규칙과 구조를 깊이 이해한 전문 모델이 필요하다는 거죠. 의료 영상, 법률 문서, 그리고 이번에는 건설 도면까지.
한국 개발자에게 주는 시사점
한국은 건설 산업 비중이 GDP의 약 15%에 달할 만큼 큰 나라예요. 대형 건설사들이 BIM(Building Information Modeling) 도입을 가속화하고 있고, 정부도 디지털 건축 허가 시스템을 추진 중이죠. 이런 흐름에서 도면 데이터 자동 추출 기술은 실무적으로 큰 가치가 있어요.
개발자 관점에서 더 흥미로운 건, "범용 AI가 못 하는 영역을 도메인 특화로 풀기"라는 비즈니스 모델이에요. 여러분이 일하는 분야에서도 비슷한 기회가 있을 수 있어요. 일반 OCR이나 LLM으로는 제대로 처리 못 하는 산업 특화 문서가 있다면, 그게 바로 스타트업 아이디어가 될 수 있다는 거죠.
마무리
"범용 AI의 한계를 도메인 전문성으로 극복한다"는 AnchorGrid의 접근은, AI 시대에 전문 지식이 여전히 강력한 경쟁력이라는 걸 보여줘요. 여러분이 일하는 분야에서 "AI가 아직 제대로 못 하는 것"은 무엇인가요? 그 gap이 다음 기회일 수 있어요.
🔗 출처: Hacker News

"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공