Postgres 데이터를 데이터 레이크로 옮기는 게 왜 그렇게 어려웠을까요
혹시 운영 중인 Postgres 데이터베이스의 데이터를 분석용으로 따로 쌓아본 적 있으세요? 보통은 이게 생각보다 골치 아픈 작업이거든요. 운영 DB에 분석 쿼리를 그대로 날리자니 서비스 성능에 영향을 줄까 무섭고, 그렇다고 따로 옮기자니 ETL 파이프라인을 짜야 하는데 이게 또 만만치 않습니다. Airbyte나 Fivetran 같은 상용 도구를 쓰자니 비용이 부담이고, Debezium + Kafka + Spark 같은 조합을 직접 구축하자니 운영 인력이 따로 필요해요.
이런 고민을 한 방에 해결해주겠다고 나선 오픈소스 프로젝트가 바로 Streambed입니다. Postgres에서 일어나는 모든 변경사항(INSERT, UPDATE, DELETE)을 실시간으로 잡아서 S3에 Apache Iceberg 포맷으로 떨궈주는 도구예요. 더 재미있는 건, Streambed 자체가 Postgres Wire Protocol을 구현하고 있어서 마치 또 하나의 Postgres 서버처럼 접속해서 쿼리를 날릴 수 있다는 점입니다.
핵심 기술: CDC와 Iceberg, 그리고 Wire Protocol
조금 더 깊이 들어가 볼게요. Streambed가 사용하는 핵심 기술은 CDC(Change Data Capture)입니다. 이게 뭐냐면, 데이터베이스에 어떤 변경이 일어났는지를 실시간으로 감지해서 다른 곳으로 흘려보내는 기술이에요. Postgres에는 logical replication이라는 기능이 있는데, 원래는 복제본을 만들 때 쓰는 기능을 살짝 비틀어서 "변경 이벤트 스트림"으로 활용하는 거죠. WAL(Write-Ahead Log, 트랜잭션 로그)을 읽어서 변경된 행만 뽑아냅니다.
그렇게 뽑은 데이터를 어디에 저장할까요? 바로 Apache Iceberg 포맷으로 S3에 저장합니다. Iceberg는 요즘 데이터 엔지니어링 업계에서 가장 핫한 테이블 포맷인데요, 쉽게 말하면 "S3에 저장된 Parquet 파일들을 마치 데이터베이스 테이블처럼 다룰 수 있게 해주는 메타데이터 레이어"입니다. 스키마가 바뀌어도 과거 데이터는 그대로 읽을 수 있고, 시간 여행(Time Travel) 쿼리도 가능하고, ACID 트랜잭션도 지원해요. Netflix가 만들어서 Apache 재단에 기증한 프로젝트인데, 지금은 Snowflake, Databricks, AWS 모두가 지원하는 사실상의 표준이 되어가고 있습니다.
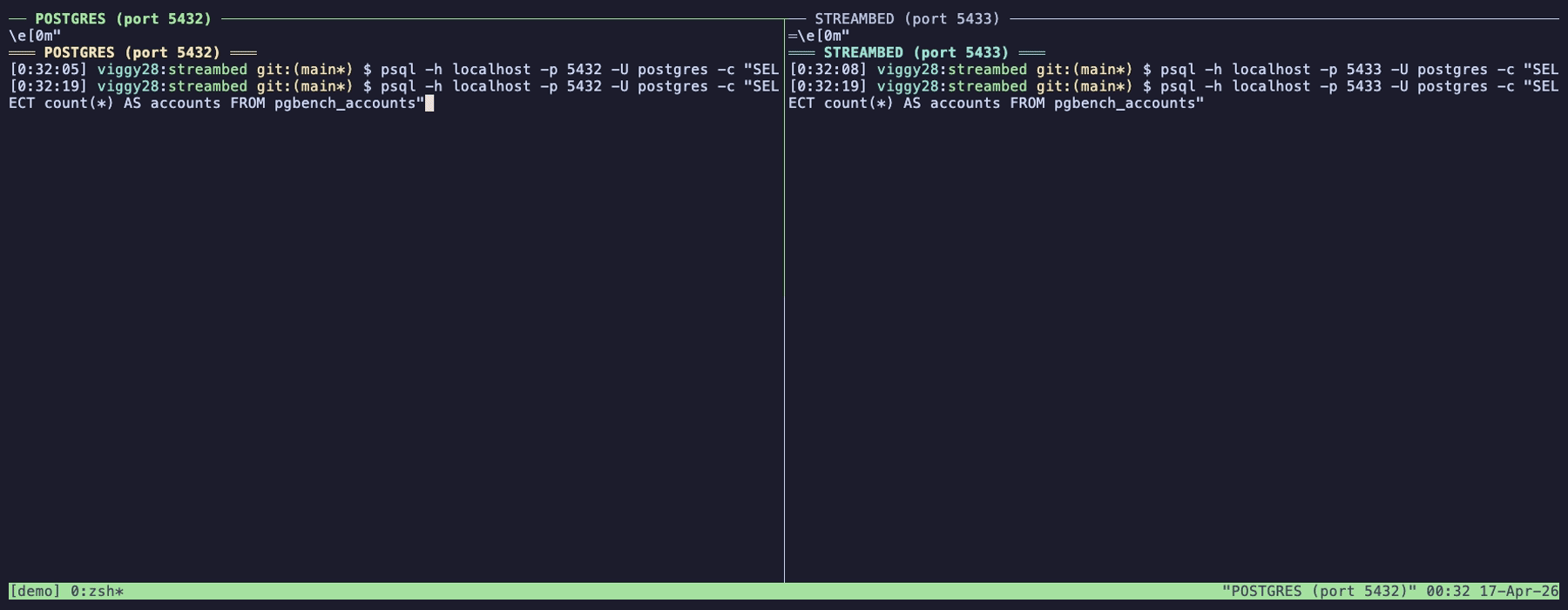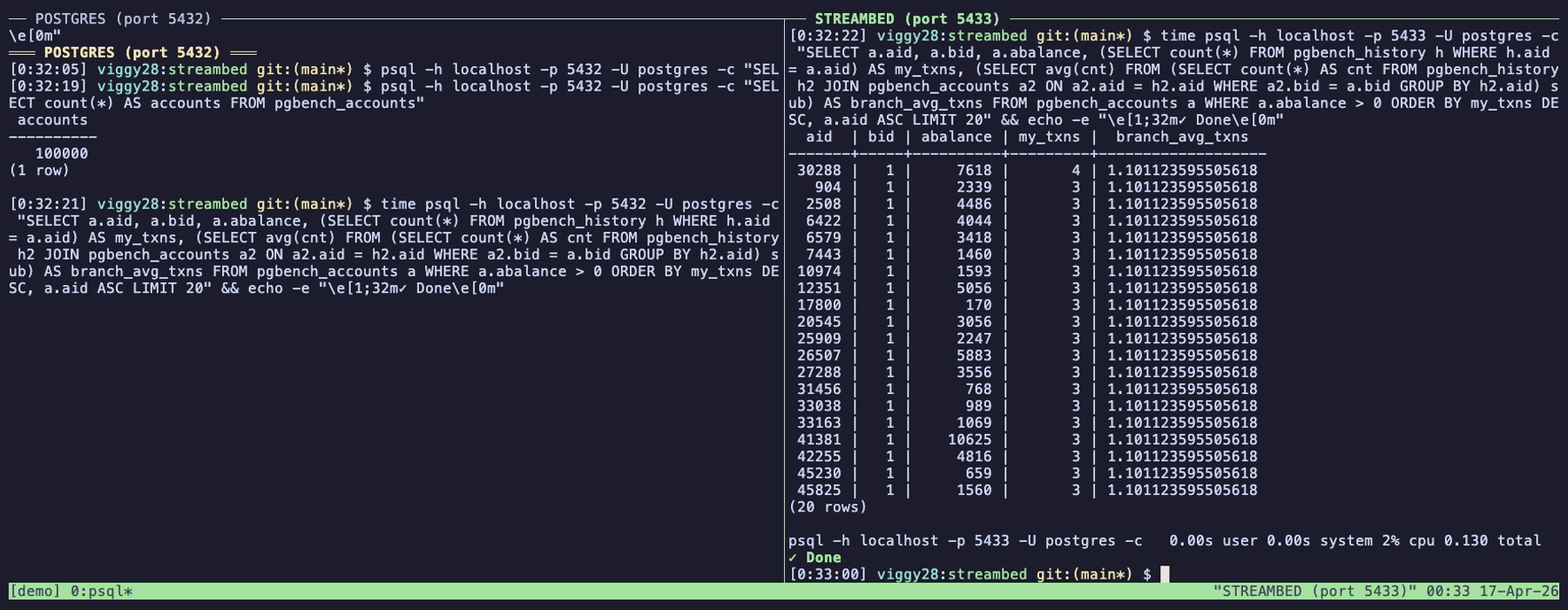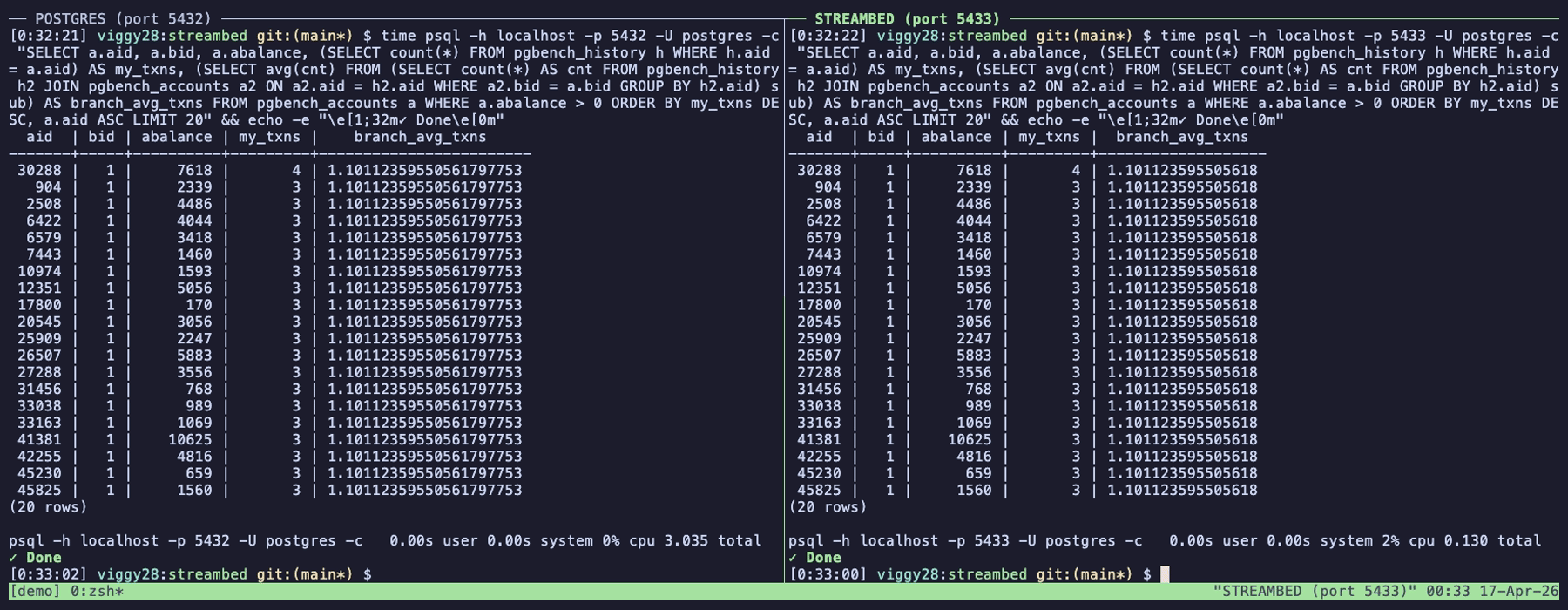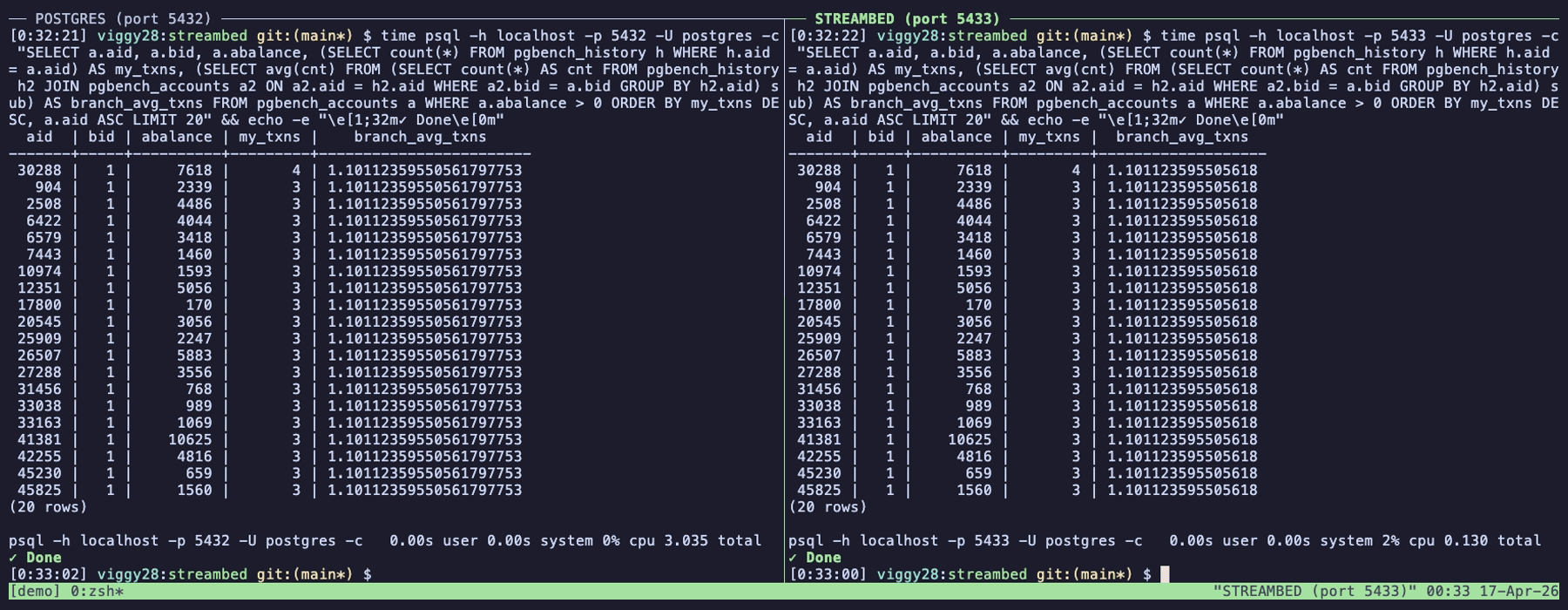
그리고 Streambed의 진짜 매력은 Postgres Wire Protocol 지원이에요. 이게 뭐냐면, psql이나 DBeaver, 또는 여러분이 쓰는 Postgres 드라이버로 그냥 Streambed에 접속하면 마치 평범한 Postgres인 것처럼 SELECT 쿼리를 날릴 수 있다는 거예요. 실제 데이터는 S3에 Iceberg로 저장돼 있는데, 사용자 입장에서는 그냥 Postgres에 쿼리하는 것처럼 느껴지죠. 이건 분석가나 BI 도구 입장에서 엄청난 장점입니다. 새로운 쿼리 언어를 배울 필요도, 새로운 드라이버를 깔 필요도 없거든요.
비슷한 도구들과 어떻게 다를까
비슷한 카테고리에 있는 도구들을 살펴보면 흐름이 보입니다. Debezium은 CDC의 원조 격이지만 Kafka가 필수라 인프라 부담이 크고요. Estuary Flow나 Materialize는 좋지만 상용 서비스 위주입니다. PeerDB(요즘 ClickHouse에 인수됨)는 Postgres → 분석 DB 복제에 특화돼 있고요. Apache SeaTunnel은 범용 ETL이라 설정이 복잡합니다.
Streambed의 차별점은 "Postgres + Iceberg + Wire Protocol"이라는 조합을 단일 바이너리로 묶어낸 가벼움이에요. 별도 Kafka 클러스터 없이 동작하고, Iceberg 카탈로그(테이블 메타데이터를 관리하는 곳)도 내장되어 있어서 시작 장벽이 낮습니다. 물론 아직 초기 프로젝트라 프로덕션에 바로 투입하기엔 검증이 더 필요하겠지만, 방향성은 분명히 매력적이에요.
한국 개발자에게 어떤 의미일까
한국에서도 데이터 레이크하우스 구축에 대한 관심이 빠르게 늘고 있습니다. 쿠팡, 토스, 당근 같은 회사들은 이미 Iceberg나 Delta Lake 기반으로 분석 인프라를 운영 중이고, 중견기업들도 이쪽으로 옮겨가는 추세거든요. 하지만 막상 스타트업이나 소규모 팀에서 직접 구축하려면 진입 장벽이 높았어요.
Streambed 같은 도구가 성숙해진다면, 작은 팀에서도 "운영 Postgres → S3 Iceberg → DuckDB/Trino로 분석" 같은 모던 데이터 스택을 큰 비용 없이 구축할 수 있게 됩니다. 특히 AWS만 잘 알고 있는 팀이라면 별도 Kafka 운영 부담 없이 시작할 수 있다는 점이 매력적이죠. 사이드 프로젝트로 데이터 파이프라인을 공부하고 싶은 분들에게도 좋은 학습 교재가 될 것 같습니다. 코드 베이스 자체가 CDC와 Iceberg의 동작 원리를 이해하기에 좋은 규모거든요.
마무리
한 줄 요약: Streambed는 Postgres의 변경사항을 S3 Iceberg로 실시간 스트리밍하면서, Postgres 프로토콜로 바로 쿼리할 수 있게 해주는 가벼운 오픈소스 CDC 도구입니다.
여러분의 회사에서는 운영 DB와 분석 DB를 어떻게 분리하고 계신가요? 직접 ETL을 짜는 편인지, 상용 도구를 쓰는 편인지, 아니면 Iceberg 같은 오픈 포맷으로 옮겨갈 계획이 있는지 궁금하네요.
🔗 출처: Hacker News

"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공