AI가 문서를 이해하는 방식, 근본부터 다시 생각하다
AI 기반 문서 어시스턴트를 만들어본 분이라면 RAG(Retrieval-Augmented Generation)라는 개념을 한 번쯤 들어보셨을 거예요. RAG는 쉽게 말하면 "AI가 대답하기 전에 관련 문서를 먼저 검색해서 참고하는 방식"인데요. 사용자가 질문을 하면, 벡터 데이터베이스에서 비슷한 내용의 문서 조각(chunk)을 찾아서 AI에게 함께 넘겨주는 거죠. 지금 대부분의 AI 문서 챗봇이 이 방식을 쓰고 있어요.
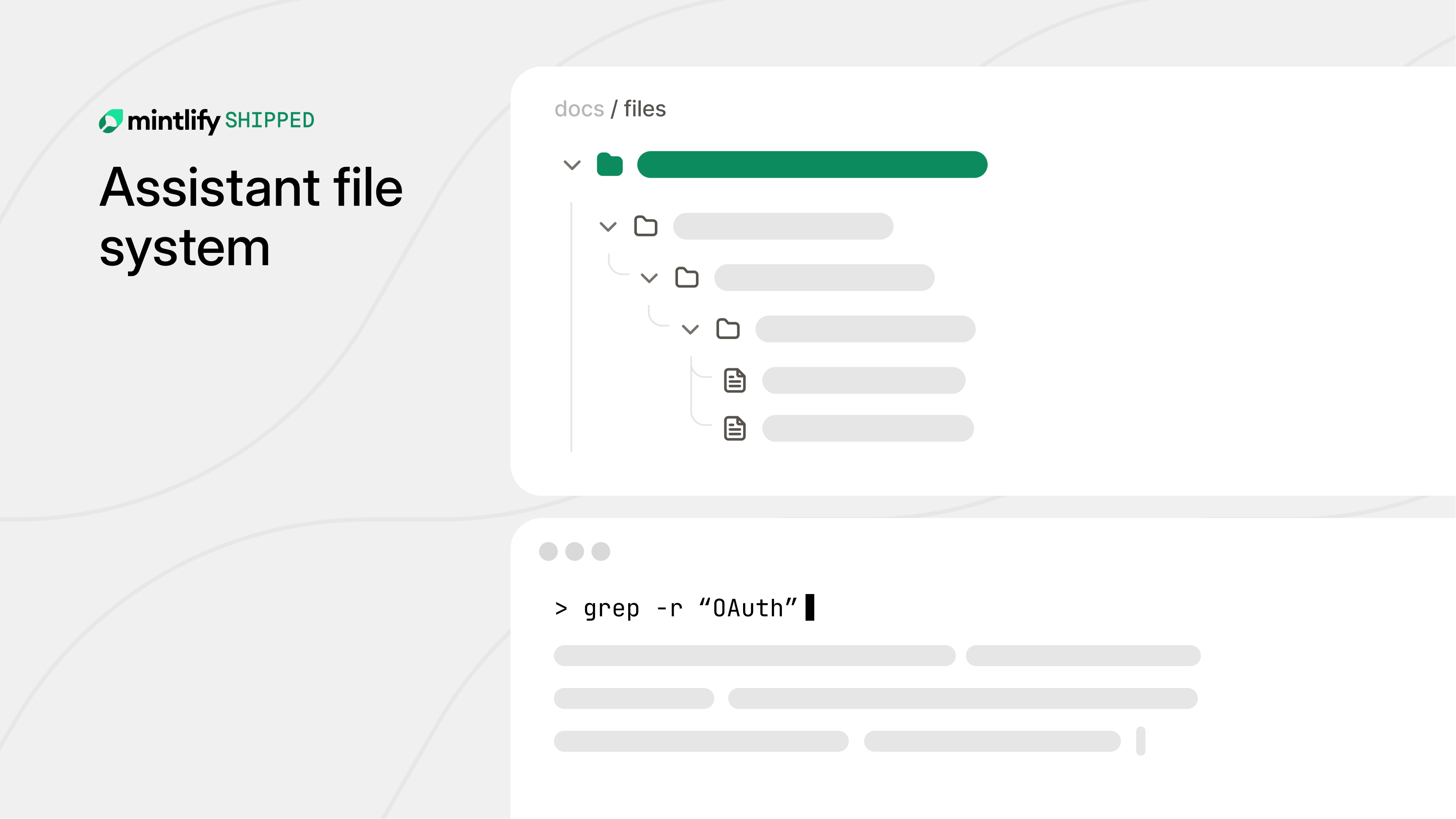
그런데 API 문서 플랫폼으로 유명한 Mintlify가 흥미로운 발표를 했어요. 자사 AI 문서 어시스턴트에서 RAG를 완전히 걷어내고, 대신 "가상 파일시스템(Virtual Filesystem)"이라는 전혀 다른 접근 방식을 도입했다는 건데요. 결과적으로 응답 품질이 크게 올라갔다고 해요.
RAG의 한계, 어디서 문제가 생기는 걸까
RAG가 나쁜 기술은 아니에요. 오히려 많은 상황에서 잘 동작하죠. 하지만 기술 문서라는 특수한 영역에서는 꽤 뚜렷한 한계가 있거든요.
첫 번째 문제는 "문맥 파편화"예요. RAG는 문서를 일정 크기로 잘라서 저장하는데, 기술 문서는 여러 페이지에 걸쳐 하나의 개념을 설명하는 경우가 많아요. 예를 들어 "인증 설정" 페이지에서 설명한 토큰 개념이 "API 호출" 페이지에서 전제 조건으로 쓰이는 식이죠. RAG는 이 관계를 잘 파악하지 못해요. 검색된 조각들이 서로 연결되지 않은 채 AI에게 전달되니까요.
두 번째는 "구조 정보 손실"이에요. 기술 문서에는 디렉토리 구조, 계층 관계, 네비게이션 순서 같은 메타 정보가 아주 중요한데, 벡터 검색은 텍스트의 의미적 유사도만 보기 때문에 이런 구조적 맥락이 날아가 버려요. 마치 책의 목차 없이 찢어진 페이지 조각만 보고 전체 내용을 이해하려는 것과 비슷하달까요.
세 번째는 "검색 품질의 불안정성"이에요. 사용자가 질문을 어떻게 표현하느냐에 따라 검색 결과가 크게 달라지거든요. 같은 내용을 물어도 단어 선택에 따라 엉뚱한 문서 조각이 올라올 수 있어요.
가상 파일시스템이라는 발상의 전환
Mintlify가 도입한 가상 파일시스템은 발상 자체가 달라요. RAG처럼 "질문에 맞는 조각을 검색"하는 게 아니라, AI 에이전트에게 파일시스템처럼 문서를 탐색할 수 있는 도구를 쥐어주는 거예요.
이게 뭐냐면, 우리가 컴퓨터에서 폴더를 열어보고 파일을 클릭해서 내용을 확인하는 것처럼, AI도 똑같이 할 수 있게 만든 거예요. AI에게 "여기 문서 폴더 구조가 이렇게 생겼어. 폴더를 열어보고, 파일을 읽어보고, 필요한 정보를 직접 찾아봐"라고 하는 거죠.
구체적으로는 AI 에이전트에게 몇 가지 도구(tool)를 제공해요. 디렉토리 목록을 볼 수 있는 도구, 특정 파일을 읽을 수 있는 도구, 그리고 키워드로 파일 내용을 검색할 수 있는 도구 같은 것들이에요. AI는 사용자의 질문을 받으면 스스로 판단해서 관련 디렉토리를 탐색하고, 필요한 파일을 열어보고, 내용을 조합해서 답변을 만들어요.
이 방식의 가장 큰 장점은 AI가 문서의 전체 구조를 이해한 상태에서 답변한다는 거예요. "인증" 폴더 아래에 "토큰", "OAuth", "API 키" 같은 하위 문서가 있다는 걸 AI가 직접 보고 파악하니까, 관련 개념들 사이의 관계를 자연스럽게 이해할 수 있거든요. RAG에서 잃어버렸던 구조적 맥락이 그대로 살아있는 셈이에요.
기존 RAG 방식과 비교하면 뭐가 다를까
RAG 파이프라인에서는 문서를 미리 전처리해야 해요. 문서를 작은 조각으로 나누고(chunking), 각 조각을 임베딩 벡터로 변환해서, 벡터 데이터베이스에 저장하는 과정이 필요하죠. 문서가 업데이트될 때마다 이 파이프라인을 다시 돌려야 하고, 청크 크기나 오버랩 같은 하이퍼파라미터도 튜닝해야 해요. 운영 복잡도가 꽤 높은 편이에요.
반면 가상 파일시스템 방식은 문서 원본을 그대로 사용할 수 있어요. 임베딩 전처리도 필요 없고, 벡터 DB 운영도 필요 없어요. 문서가 업데이트되면 파일만 바꾸면 되니까 파이프라인이 훨씬 단순해지죠. 물론 에이전트가 여러 번 도구를 호출해야 하니까 응답 지연(latency)은 늘어날 수 있는데, Mintlify는 이 부분을 파일시스템 구조의 사전 인덱싱과 캐싱으로 최적화했다고 해요.
다만 이 접근법이 모든 상황에 정답인 건 아니에요. 문서 규모가 아주 크거나, 비정형 데이터가 많거나, 단순 Q&A 위주의 서비스라면 RAG가 여전히 효율적일 수 있어요. 가상 파일시스템은 특히 체계적으로 정리된 기술 문서, API 레퍼런스처럼 구조가 중요한 문서에 잘 맞는 방식이에요.
업계 맥락: 에이전트 기반 아키텍처의 부상
사실 이 접근법은 더 넓은 트렌드의 일부예요. AI 업계 전반에서 "단순 프롬프트 + 검색"에서 "에이전트가 도구를 활용하는 방식"으로 패러다임이 이동하고 있거든요. Anthropic의 Claude가 컴퓨터를 직접 조작하는 Computer Use, OpenAI의 함수 호출(Function Calling), 그리고 최근 뜨고 있는 MCP(Model Context Protocol) 같은 것들이 모두 같은 맥락이에요.
문서 어시스턴트 분야에서도 비슷한 움직임이 있어요. Cursor나 GitHub Copilot 같은 코딩 어시스턴트들도 단순히 코드 조각을 검색하는 것에서, 프로젝트 구조를 이해하고 파일을 탐색하는 에이전트 방식으로 진화하고 있죠. Mintlify의 사례는 이런 흐름이 개발자 도구 전반으로 확산되고 있다는 신호로 볼 수 있어요.
한국 개발자에게 주는 시사점
사내 문서 챗봇이나 고객 지원 AI를 만들고 계신 분들이라면 주목할 만한 사례예요. 특히 개발 문서, 사내 위키, API 가이드처럼 구조가 잘 잡혀 있는 문서를 다루는 경우, RAG 대신 에이전트 + 파일시스템 탐색 방식을 실험해볼 가치가 있어요.
구현 난이도도 의외로 높지 않아요. 요즘 LLM들은 대부분 함수 호출을 지원하니까, 파일 목록 조회, 파일 읽기, 텍스트 검색 정도의 도구만 만들어주면 에이전트가 알아서 탐색해요. 오히려 RAG 파이프라인의 청킹 전략, 임베딩 모델 선택, 벡터 DB 운영 같은 복잡한 과정이 사라지니까 전체 시스템이 더 단순해질 수도 있어요.
정리
"문서를 잘게 쪼개서 검색한다"는 RAG의 기본 전제를 뒤집고, "AI에게 문서를 직접 탐색하게 한다"는 발상의 전환이 인상적인 사례예요. 여러분이 만들고 있는 AI 서비스에서, 혹시 RAG의 한계 때문에 답변 품질이 아쉬운 부분이 있다면, 이런 에이전트 기반 접근을 고려해보는 건 어떨까요?
🔗 출처: Hacker News

"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공