분산 시스템을 만들다 보면 반드시 마주치는 악몽 같은 문제가 하나 있어요. 바로 "정확히 한 번(exactly-once)" 실행 보장인데요. 예를 들어 결제가 완료되면 포인트를 적립해주는 로직을 생각해볼게요. 결제 처리가 끝난 직후, 포인트 적립 직전에 서버가 죽어버리면 어떻게 될까요? 재시작 후 처음부터 다시 실행하면 결제가 두 번 될 수 있고, 그냥 넘어가면 포인트 적립이 누락되죠. 이 문제를 다루는 흥미로운 관점의 글이 나왔어요. 워크플로 엔진을 만드는 DBOS 팀이 쓴 글인데, 요지는 "Postgres 트랜잭션이야말로 분산 시스템의 숨겨진 초능력"이라는 거예요.
기존 방식은 왜 복잡할까요
이 문제를 푸는 전통적인 방법은 여러 겹의 장치를 쌓는 거였어요. 먼저 Kafka 같은 메시지 큐를 두고 작업을 이벤트로 흘려보내고요. DB에 데이터를 쓰는 것과 메시지를 발행하는 걸 원자적으로 묶기 위해 아웃박스 패턴이라는 걸 써요. 이게 뭐냐면, 메시지를 큐에 직접 보내는 대신 DB의 outbox 테이블에 같은 트랜잭션으로 저장해두고, 별도 프로세스가 그 테이블을 읽어서 큐로 전달하는 방식이에요. 그리고 소비자 쪽에서는 같은 메시지가 두 번 와도 안전하도록 멱등성 키(같은 요청을 구분하는 고유 식별자)를 관리하죠. 동작은 하는데, 컴포넌트가 늘어날수록 장애 지점도 늘어나고 디버깅도 어려워져요.
핵심 아이디어: 워크플로 상태를 데이터 옆에 두자
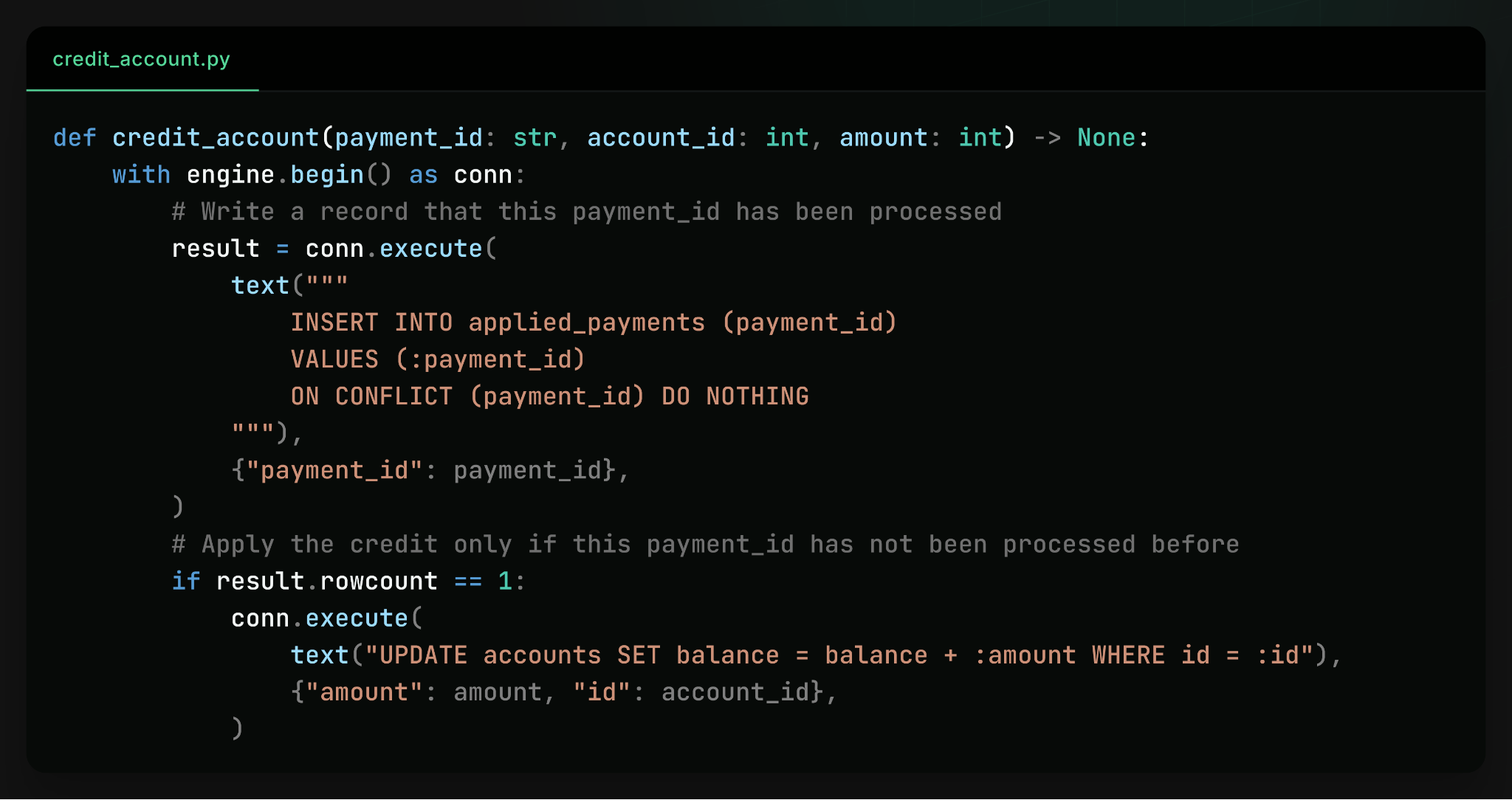
DBOS의 주장은 의외로 단순해요. 워크플로의 진행 상태, 그러니까 "이 작업이 몇 번째 단계까지 실행됐는지"를 기록하는 체크포인트를 별도 시스템이 아니라 애플리케이션 데이터가 있는 바로 그 Postgres에 저장하자는 거예요. 이렇게 하면 마법 같은 일이 벌어지는데요. 비즈니스 데이터 변경(포인트 적립)과 워크플로 체크포인트 기록("2단계 완료")을 하나의 트랜잭션으로 커밋할 수 있게 돼요. 트랜잭션은 원자적이니까 둘 다 반영되거나 둘 다 반영되지 않거나, 두 가지 경우만 존재해요. "실행은 됐는데 기록이 안 된" 애매한 상태가 원천적으로 사라지는 거죠.
이런 방식을 내구성 있는 실행(durable execution)이라고 불러요. 함수의 각 단계 실행 결과를 DB에 기록해두고, 프로세스가 죽었다 살아나면 기록을 보고 이미 완료된 단계는 건너뛰고 딱 멈춘 지점부터 이어서 실행하는 거예요. 게임의 세이브 포인트와 똑같은 개념이에요. 보통 이런 시스템은 워크플로 상태 저장소와 애플리케이션 DB가 분리되어 있어서 둘 사이의 정합성이 또 다른 골칫거리가 되는데, 같은 DB를 쓰면 그 문제가 통째로 없어져요. 분산 트랜잭션이나 2단계 커밋(two-phase commit) 같은 무겁고 까다로운 도구 없이도요.
Temporal과는 뭐가 다를까요
내구성 있는 실행 분야에서 가장 유명한 건 Temporal이에요. Uber의 Cadence에서 갈라져 나온 프로젝트인데, 별도의 오케스트레이터 서버를 운영해야 하고 워크플로 상태도 그쪽에 저장돼요. AWS Step Functions도 비슷하게 외부 서비스가 상태를 관리하죠. 반면 DBOS는 라이브러리 방식이에요. 앱 코드에 데코레이터를 붙이면 상태가 내가 쓰던 Postgres에 저장되는 구조라, 새로 운영할 인프라가 없어요. 대신 상태 저장소가 Postgres 하나에 묶인다는 제약이 생기는데, 이 글은 그 제약이 약점이 아니라 오히려 강점이라고 주장하는 셈이에요. 최근의 "그냥 Postgres 쓰세요" 트렌드와도 맞닿아 있고요. 큐가 필요하면 SKIP LOCKED로, pub/sub은 LISTEN/NOTIFY로, 벡터 검색은 pgvector로 해결하자는 흐름 말이에요.
우리에게 주는 시사점
한국의 많은 팀이 마이크로서비스 전환과 함께 Kafka, Redis, 별도 워크플로 엔진을 겹겹이 도입하는데요. 트래픽 규모가 Postgres 한 대(혹은 리플리카 몇 대)로 감당되는 수준이라면, 이 접근이 아키텍처를 극적으로 단순하게 만들어줄 수 있어요. 물론 한계도 분명해요. 이 마법은 모든 상태가 하나의 DB에 있을 때만 성립하거든요. DB를 샤딩하거나 서비스마다 다른 저장소를 쓰는 순간 다시 분산 시스템 문제로 돌아와요. 그러니 "우리 규모에 정말 분산이 필요한가?"를 먼저 묻는 게 순서겠죠.
한 줄로 정리하면, 분산 시스템의 어려운 문제 상당수는 상태를 한곳에 모으면 트랜잭션이라는 40년 묵은 도구로 풀린다는 이야기예요. 여러분 팀은 어떠세요? 지금 운영 중인 큐와 워크플로 인프라, 정말 Postgres 하나로는 안 되는 규모인가요?
🔗 출처: Hacker News
TTJ 코딩클래스 정규반
월급 외 수입,
코딩으로 만들 수 있습니다
17가지 수익 모델을 직접 실습하고, 1,300만원 상당의 자동화 도구와 소스코드를 받아가세요.
"비전공 직장인인데 반년 만에 수익 파이프라인을 여러 개 만들었습니다"
실제 수강생 후기- 비전공자도 6개월이면 첫 수익
- 20년 경력 개발자 직강
- 자동화 프로그램 + 소스코드 제공