RNN은 왜 앞부분을 자꾸 까먹을까
문장을 처리하는 AI 모델 중에 순환신경망(RNN, Recurrent Neural Network)이라는 게 있어요. 이게 뭐냐면, 단어를 하나씩 순서대로 읽으면서 지금까지 읽은 내용을 "기억"이라는 상태(state)에 담아 다음 단어로 넘겨주는 구조예요. 사람이 책을 왼쪽에서 오른쪽으로 읽으면서 앞 내용을 머릿속에 담아두는 것과 비슷하죠. 그런데 이 RNN에는 유명한 약점이 하나 있어요. 문장이 길어지면 앞부분에서 봤던 정보를 자꾸 까먹는다는 거예요. 이번에 어떤 분이 블로그에서, 이 오래된 문제를 '행렬 직교화(matrix orthogonalization)'라는 방법으로 다뤄보는 이야기를 정리했는데요, 개념 자체가 흥미로워서 쉽게 풀어드릴게요.
곱하고 또 곱하면 신호가 사라지거나 폭발해요
RNN이 한 단어를 넘어갈 때마다 내부적으로는 기억 상태에 어떤 행렬(matrix, 숫자들을 격자로 늘어놓은 표)을 곱해요. 문제는 이 곱셈을 수십, 수백 번 반복한다는 거예요.
숫자 하나로 비유해볼게요. 0.9를 계속 곱하면 어떻게 되죠? 0.9, 0.81, 0.73... 이렇게 점점 0에 가까워지다가 결국 사라져요. 반대로 1.1을 계속 곱하면 1.1, 1.21, 1.33... 이렇게 눈덩이처럼 커지다가 폭발해버려요. 행렬도 똑같아요. 곱셈을 반복하면 앞부분 정보가 스르륵 사라지거나(그래디언트 소실, vanishing gradient), 반대로 값이 통제 불능으로 커져버려요(그래디언트 폭발, exploding gradient). 그래서 문장 앞머리에서 본 정보가 뒤까지 살아남지를 못하는 거예요.
'직교 행렬'은 크기를 그대로 지켜줘요
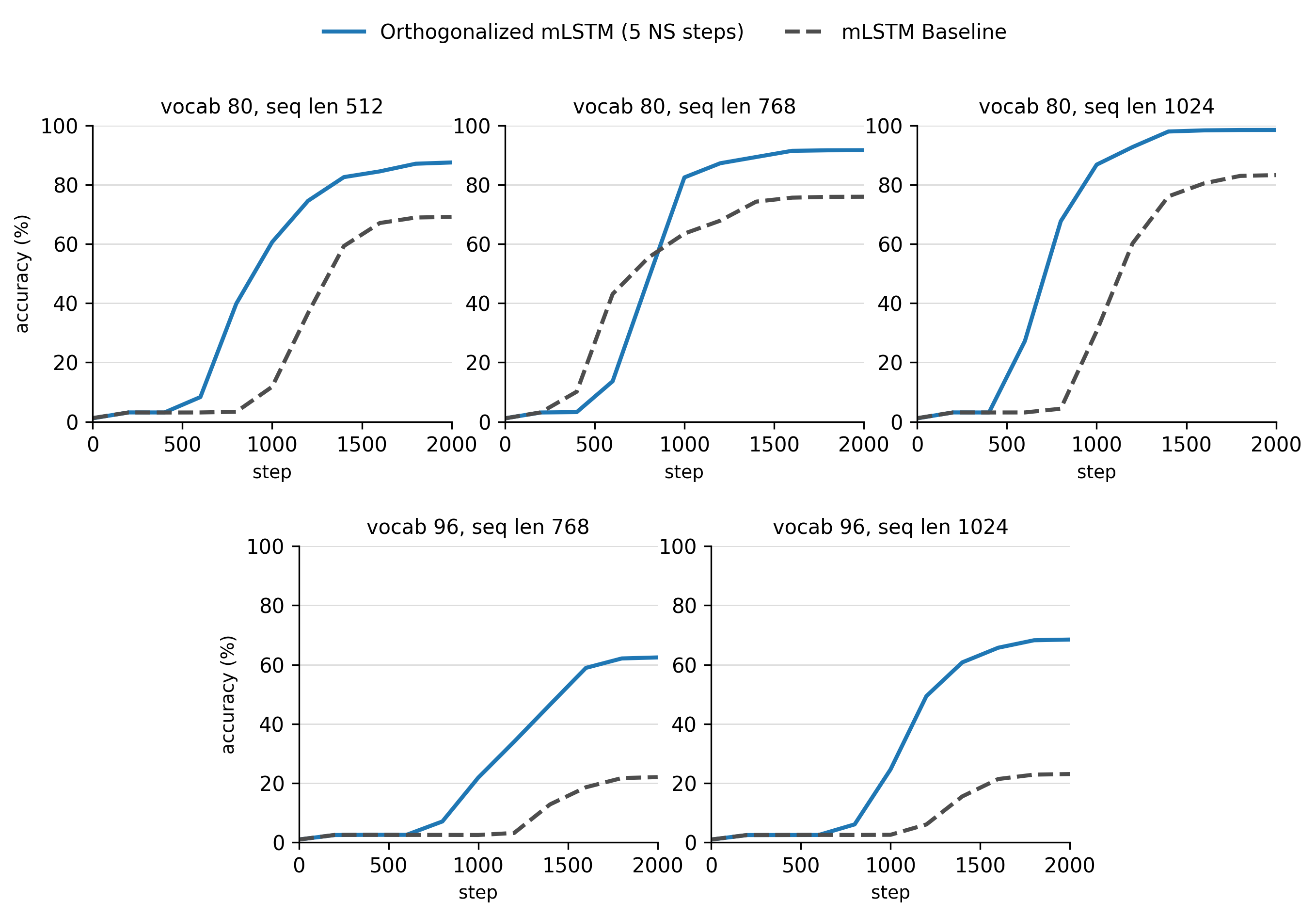
여기서 등장하는 게 직교 행렬(orthogonal matrix)이에요. 이게 뭐냐면, 어떤 벡터에 곱해도 그 벡터의 "길이(크기)"를 절대 바꾸지 않는 특별한 행렬이에요. 방향만 빙글 돌려줄 뿐(회전), 크기는 그대로 두는 거죠. 수학적으로는 이 행렬의 특이값(singular value)이 전부 1이라고 표현해요.
크기를 안 바꾼다는 게 왜 중요할까요? 아까 0.9나 1.1을 계속 곱하면 문제가 생겼잖아요. 그런데 크기 1을 계속 곱하면? 1, 1, 1... 아무리 반복해도 그대로예요. 즉 기억 상태에 직교 행렬만 곱하도록 강제하면, 정보가 백 단계, 이백 단계를 지나도 줄지도 커지지도 않고 온전히 보존돼요. 학습에 쓰이는 그래디언트(모델이 오답을 고칠 때 참고하는 신호)도 마찬가지로 살아남고요. 그래서 훨씬 긴 문맥을 안정적으로 기억할 수 있게 되는 거예요.
오래됐지만 여전히 뜨거운 아이디어
사실 이 방향의 연구는 꽤 됐어요. 몇 년 전부터 유니터리 RNN(unitary RNN), 직교 RNN(orthogonal RNN) 같은 이름으로 "회전 행렬만 쓰는 순환신경망"들이 제안돼 왔거든요. 다만 학습 도중에 행렬을 계속 직교 상태로 유지하는 게 은근히 까다로워요. 그래서 케일리 변환(Cayley transform)이나 하우스홀더 반사(Householder reflection) 같은 수학 도구로, 학습하는 내내 행렬을 직교의 세계 밖으로 벗어나지 않게 붙잡아 두는 여러 기법이 나왔어요.
이 주제가 지금 다시 주목받는 이유는, 요즘 자주 언급되는 상태공간 모델(SSM)이나 Mamba 같은 최신 시퀀스 모델들도 결국 "긴 시퀀스에서 정보를 어떻게 안정적으로 흘려보낼까"라는 똑같은 고민을 공유하기 때문이에요. 트랜스포머가 어텐션으로 이 문제를 정면 돌파했다면, 직교화 계열은 '곱셈의 안정성'이라는 다른 길로 같은 산을 오르는 셈이죠.
우리가 얻어갈 것
실무에서 매일 직교 RNN을 직접 짜는 사람은 드물지만, 여기서 배울 원리는 넓게 쓸모가 있어요. "같은 연산을 아주 여러 번 반복할 때는, 그 연산이 값을 키우지도 줄이지도 않게 만드는 게 안정성의 핵심"이라는 감각이에요. 이건 딥러닝의 가중치 초기화, 정규화(normalization) 기법, 심지어 수치 계산 전반을 관통하는 아이디어거든요. 긴 시퀀스를 다루는 모델을 튜닝하다가 학습이 자꾸 발산하거나 초반 정보가 사라진다면, "혹시 반복 곱셈의 크기가 1에서 멀어진 게 아닐까?"를 떠올려보면 좋아요.
여러분은 반복되는 연산의 안정성 때문에 골치 아팠던 경험, 딥러닝 말고 다른 곳에서도 겪어본 적 있으신가요?
🔗 출처: Hacker News